《计算机网络》笔记-第2章应用层
[TOC]
0. 前言
Chapter 2 Application Layer
《计算机网络——自顶向下方法》第2章的学习笔记。笔记中,部分标题经过我修改,跟书本不一致。
应用层是相对贴近于我们的一层,也是相对简单的一层。
正如其名,它是为了处理应用 application 之间通信而存在的,比如:浏览器应用如何从云端服务器应用中获取资源(我们需要知道资源的位置、资源的数据格式、服务器的状态等);邮箱应用如何将邮件发送给另一个邮箱应用;QQ应用如何与另一个QQ应用通信等等。
1. Principles of Network Applications(应用层协议原理)
1.1. Network Application Architectures(网络应用程序体系结构)
主要包括两种主流体系结构:
客户-服务器体系结构:有一个总是打开的主机称为服务器,它服务于许多来自客户主机的请求。服务器常存在于配备了大量主机的数据中心中。
对等(P2P, peer to peer)体系结构:对位于数据中心的专用服务器有最小(或没有)依赖。使用这种体系的应用包括:文件共享、因特网电话、视频会议等。对于这些应用,服务器被用于跟踪用户的IP地址,但用户到用户的报文在用户主机之间直接发送,无须经过中间服务器。
1.2. Client and Server(客户与服务器)
我们可以知道,同一台主机上的不同进程,可以进行进程间通信。而不同主机(端系统)上的进程,则通过跨越计算机网络交换报文进行通信。
接下来,我们对相互通信的两个进程,作如下定义:
在一对进程之间的通信会话场景中,发起通信的进程被标识为客户(client),等待联系的进程被标识为服务器(server)。
所以,特别注意!!!在网络通信中,服务器通常指运行在目标主机上的进程(程序)。 例如,在Web应用程序中,一个浏览器(客户进程)与一个Web服务器(服务器进程)交换报文。
有时,我们也称应用程序的客户端和服务端。
那么,客户进程是如何找到服务器进程的呢?
- 目标主机由其IP地址标识。
- 目标主机上的服务器进程则由端口号来标识。端口号大小在
0 ~ 65535之间,其中0 ~ 1023为周知端口号,例如,Web服务器通常用80端口号标识,邮件服务器用25端口号标识。
1.3. 套接字
那么,进程是如何向网络发送报文的呢?是通过一个称为 套接字(socket) 的软件接口。
套接字是一台主机中应用层与运输层之间的接口,也是应用程序和网络之间的API。
1.4. 可供使用的运输服务和因特网提供的运输服务
当开发一个应用时,必须选择一种可用的运输层协议。
我们通常将运输层协议提供的服务大体分为四类:
- **可靠数据传输(reliable data transfer),确保数据交付的服务。能容忍数据丢失的应用,被称为容忍丢失的应用(loss-tolerant applications)**,如交谈式音频/视频,它们能够承受一定量的数据丢失。
- 吞吐量,能够确保吞吐量恒定。具有吞吐量要求的应用,被称为**带宽敏感的应用(bandwidth-sensitive applications);对吞吐量要求较低的应用,被称为弹性应用(elastic applications)**。
- 定时。
- 安全性。
因特网提供的运输服务如下:
TCP:
- 客户与服务器间,在握手阶段会建立TCP连接,该连接是全双工的
- 无差错、按顺序交付数据
- 拥塞控制机制,网络出现拥塞时,将会抑制发送进程
UDP:
- 无连接的,没有握手阶段
- 不可靠数据传输、乱序到达
**SSL(Secure Sockets Layer, 安全套接字层)**,TCP的加强版本。
因特网中的常见应用及其应用层协议和支撑的运输协议:

1.5. Application-Layer Protocols(应用层协议)
我们通过把报文(其实就是数据)发送进套接字,从而实现网络进程间的通信。但如何构造这些报文?报文中各个字段的含义是什么?这些问题将由应用层协议解决。
应用层协议(application-layer protocol) 主要定义了:
- 交换的报文类型
- 各种报文的语法
- 字段的语义
- 确定一个进程何时以及如何发送报文
- 对报文响应的规则
部分应用层协议是由 RFC文档(包含所有互联网标准的文档) 定义的,大家都必须遵守。例如,Web的应用层协议HTTP(RFC 2616),如果浏览器遵守HTTP协议,那它就能访问所有遵守HTTP协议的Web服务器(进程),并获取Web页面。因此,应用层协议HTTP只是Web应用的一个部分。
还有部分应用协议是专用的。例如,Skype软件就使用了专用的应用层协议。
特别注意:应用层协议是可以自定义的!用户可以编写程序调用套接字接口,直接支配运输层。此时,如果用户对传入套接字的数据进行规范,那么这个规范就是用户自定义的应用层协议。
1.6. Network Applications Covered in This Book(本书涉及的网络应用)
在本章,将详细讨论5种重要应用:
- Web,使用HTTP协议
- 文件传输
- 电子邮件,使用SMTP协议
- 目录服务,使用DNS协议
- 流式视频和P2P
2. Web 与 HTTP 协议
1990s,一个新型的因特网应用————万维网(World Wide Wed, 简称www或web),诞生了。
先介绍一部分Web术语:
- Web页面(Web page,也叫文档),由多个对象组成。
- 对象,是一个文件,诸如一个HTML文件、一个图片或一个Java小程序。如果一个Web页面包含HTML文本和5张图片,那么这个Web页面有6个对象。
- Web浏览器,实现了HTTP的客户端。例如,谷歌、火狐、IE浏览器。通常,“客户”==“浏览器”。
- Web服务器,实现了HTTP的服务端。例如,Apache、Tomcat。
2.1. Overview of HTTP
**HTTP(HyperText Transfer Protocol,超文本传输协议)**,是Web应用使用的应用层协议。
HTTP在 [RFC 1945] 和 [RFC 2616] 中进行定义。
HTTP定义了客户和服务器交换报文的方式,以及这些报文的结构。
HTTP使用TCP作为它的支撑运输协议。
HTTP是 无状态协议(stateless protocol) ,不存储任何关于该客户的状态信息。
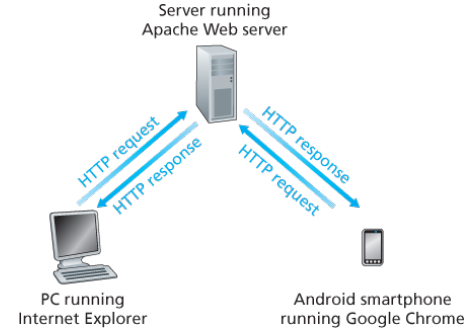
2.2. Non-Persistent and Persistent Connections(非持续连接和持续连接)
- 非持续连接(non-persistent connections),每个请求-响应对经过各自单独的TCP连接发送。
- 持续连接(persistent connections),所有请求-响应对经过同一个TCP连接发送。
2.2.1. HTTP with Non-Persistent Connections(采用非持续连接的 HTTP)
每个对象通过单独的TCP连接发送。
假设,一个Web页面包含一个HTML文件和10个图片,这11个对象位于同一台服务器上,并且该HTML文件的URL为:http://www.study.com/home.index。
非持续连接的HTTP请求响应过程如下:
- 浏览器(HTTP客户端)在80端口,向服务器
www.study.com的80端口发起一个TCP连接。 - HTTP客户端经它的套接字向服务器发送一个HTTP请求报文,报文中包含路径名
/home.index。 - HTTP服务器通过它的套接字接收到请求报文,并检索出相应对象,在HTTP响应报文中封装该对象,最后向客户发送响应报文。
- HTTP服务器通知TCP断开连接。
- HTTP客户端接收响应报文,TCP连接关闭。
- 对HTML文件中的每个图片对象重复上述步骤。
非持续连接的缺点:
- 必须为每个请求建立和维护全新的TCP连接,增加Web服务器负担。
- 每个对象都将经受两倍RTT(round-trip time,往返时间,分组从客户到服务器再到客户的时间),增加总体时延。
2.2.2. HTTP with Persistent Connections(采用持续连接的 HTTP)
在同个服务器上的多个对象甚至多个Web页面通过同一个TCP连接发送。
持续连接的HTTP请求响应过程如下:
- 浏览器(HTTP客户端)在80端口,向服务器
www.study.com的80端口发起一个TCP连接。 - HTTP客户端经它的套接字向服务器发送一个HTTP请求报文,报文中包含路径名
/home.index。 - HTTP服务器通过它的套接字接收到请求报文,并检索出相应对象,在HTTP响应报文中封装该对象,最后向客户发送响应报文。
- 对HTML文件中的每个图片对象重复2、3步骤。
- HTTP服务器通知TCP断开连接。
- HTTP客户端接收响应报文,TCP连接关闭。
持续连接的缺点:
- 对于现在的广泛普及的宽带连接来说,Keep-Alive也许并不像以前一样有用。web服务器会保持连接若干秒(Apache中默认15秒),这与提高的性能相比也许会影响性能。
- 对于单个文件被不断请求的服务(例如图片存放网站),Keep-Alive可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
HTTP协议发展,与非持续和持续连接:
- HTTP/1.0 只能使用非持续连接
- HTTP/1.1 默认使用持续连接,可以配置非持续连接;
- HTTP/2 允许在相同连接中多个请求和回答交错。
2.3. HTTP Message Format(HTTP 报文格式)
HTTP报文有两种:请求报文和响应报文。
2.3.1. HTTP Request Message(HTTP 请求报文)
一个示例如下:

一个请求报文有一行或者多行,分为三部分:
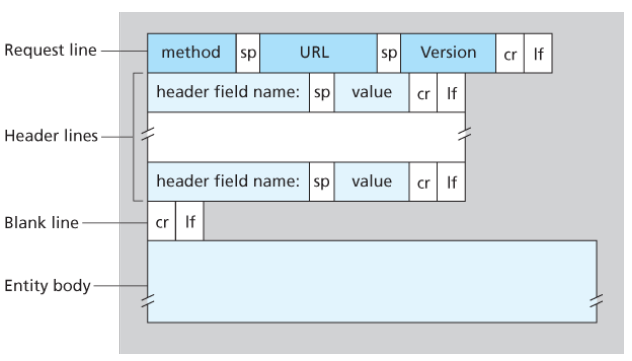
**请求行(request line)**,在第1行,有3个字段:
方法,包含以下值(前3种为HTTP1.0,后5种为HTTP1.1新增):
GET:请求指定的页面信息,并返回实体主体。在请求URL中包含表单数据POST:在实体体中包含表单数据HEAD:当服务器收到一个HEAD请求时,将会用一个HTTP报文进行响应,但是并不返回请求对象。应用程序常用HEAD方法进行调试跟踪PUT:它允许用户上传对象到指定的Web服务器上指定的路径DELETE:允许用户删除Web服务器上的对象CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器OPTIONS:允许客户端查看服务器的性能TRACE:回显服务器收到的请求,主要用于测试或诊断
URL:又称统一资源定位符,其标准格式如下:
1
协议类型://服务器IP地址[:需要时加上端口号]/路径/文件名
HTTP版本:当下常见的为HTTP/1.1
首部行(header lines),第2~n行,每行分为首部字段名和值两个字段。常见的首部行如下:
Host:初始URL中的主机和端口。Connection:值为keep-alive时,表示为持续连接;值为close时,表示不需要持续连接。HTTP1.1默认持续连接。User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。Accept:浏览器可接受的媒体类型。如:1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Charset:浏览器可接受的字符集。Accept-Encoding:浏览器能够进行解码的数据编码方式。例如:Accept-Encoding: gzip, deflate, brAccept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。Content-Length:表示请求消息正文的长度。Cookie:会话层信息,这是最重要的请求头信息之一。If-Modified-Since:只有当所请求的内容在指定的日期之后又经过修改才返回它,否则返回304“Not Modified”应答。Referer:包含一个URL,用户从该URL代表的页面出发访问当前请求的页面。
实体体(entity body)/请求体,使用POST方法时使用该实体。
2.3.2. HTTP Response Message(HTTP 响应报文)
一个示例如下:
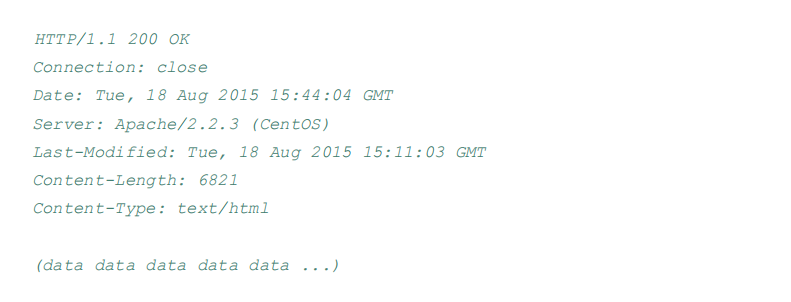
响应报文也分为三部分:
**状态行(status line)**,状态行包括3个字段:
HTTP协议版本
状态码。由三个十进制数字组成,第一个数定义了状态码的类型。常见如下:
- 1xx: 信息。服务器收到请求,需要请求者继续执行操作
- 100 Continue: 继续。客户端应继续其请求
- 101 Switching Protocols: 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议
- 2xx: 成功。操作被成功接收并处理
- 200 OK: 请求成功。一般用于GET与POST请求
- 3xx: 重定向。需要进一步的操作以完成请求
- 301 Moved Permanently: 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替
- 304 Not Modified: 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源
- 305 Use Proxy: 使用代理。所请求的资源必须通过代理访问
- 4xx: 客户端错误。请求包含语法错误或无法完成请求
- 400 Bad Request: 客户端请求的语法错误,服务器无法理解
- 403 Forbidden: 服务器理解请求客户端的请求,但是拒绝执行此请求
- 404 Not Found: 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置”您所请求的资源无法找到”的个性页面
- 5xx: 服务器错误。服务器在处理请求的过程中发生了错误
- 500 Internal Server Error: 服务器内部错误,无法完成请求
- 502 Bad Gateway: 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求
- 504 Gateway Time-out: 充当网关或代理的服务器,未及时从远端服务器获取请求
- 505 HTTP Version not supported: 服务器不支持请求的HTTP协议的版本,无法完成处理
- 1xx: 信息。服务器收到请求,需要请求者继续执行操作
相应状态信息
首部行(header line)
Connection:值为keep-alive时,表示与客户保持TCP连接;值为close时,告诉客户发送报文后将关闭TCP连接。Content-Encoding: 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。例如:Content-Encoding:gzipContent-Type: 表示后面的文档属于什么MIME类型。例如:Content-Type: text/html;charset=utf-8Date: 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。Expires: 响应过期的日期和时间。Last-Modified: 文档的最后改动时间。Server: 服务器名字。Set-Cookie: 设置和页面关联的Cookie。
**实体体(entity body)**,响应给客户的数据,如HTML、图片等
2.4. Cookies
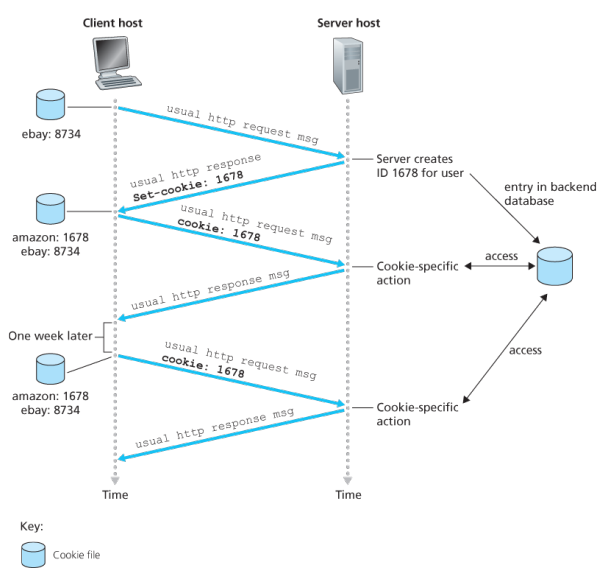
众所周知,HTTP是无状态协议。cookie[RFC 6265] 在HTTP之上建立一个用户会话层,使得Web网站可以记录用户状态。网站的自动登录,大部分都是基于cookie实现的。
cookie包含4个部分:
- HTTP响应报文中的一个
Set-Cookie首部行 - HTTP请求报文中的一个
Cookie首部行 - 用户浏览器储存cookie的文件。文件中的一行包括:服务器的主机名 和 服务器传来的cookie
- 服务端cookie对应的数据库,又称
session
示例如下:
2.5. Web Caching(Web 缓存)
Web缓存器(Web Cache),也叫代理服务器(proxy server)。它通常被放置在离用户较近的地方,可以缓存用户最近请求过的对象的副本。类似于操作系统中的高速缓存。其实践的命中率通常在0.2~0.7之间。
Web缓存器有两大好处:
- 可以大大减少对客户请求的响应时间
- 能从整体上减少因特网上的Web流量
其工作过程如下(需要先配置浏览器指向Web缓存器):

2.6. The Conditional GET(条件 Get 方法)
**条件Get方法(conditional GET)**,允许缓存器证实它储存的对象是最新的。它有以下两个特征:
- 请求报文使用GET方法
- 请求报文中包含
If-Modified-Since首部行
示例:

该条件GE报文会告诉服务器,仅当自指定日期之后该对象被修改过,才发送该对象。如果没有被修改,服务器就会返回304 Not Modified的响应报文。
3. 电子邮件与 SMTP 协议
当因特网还在襁褓中时,电子邮件已经成为最为流行的应用程序了。
电子邮件系统包含三个主要组成部分:
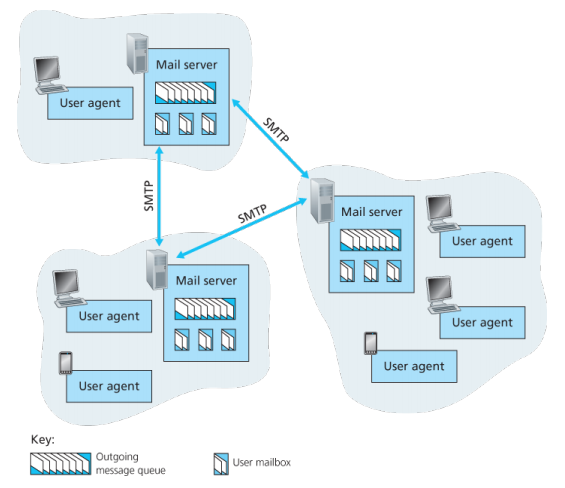
- 用户代理(user agent):用户写完邮件时,用户代理会将邮件发送到邮件服务器,被放置在邮件服务器的外出报文队列(Outgoing message queue) 中;用户阅读邮件时,用户代理从邮件服务器的指定邮箱中取得该报文。
- **邮件服务器(mail server):存放邮件的服务器,每个用户在邮件服务器上,都有一个用户邮箱(user mailbox)**,管理和维护着发送给用户的报文。负责将邮件发送到指定邮件服务器,也负责接收邮件,既是SMTP客户端,又是SMTP服务端。
- SMTP:应用层协议,使用TCP可靠数据传输服务。
3.1. SMTP
SMTP(Simple Mail Transfer Protocol),又称简单邮件传输协议,问世于1982年。
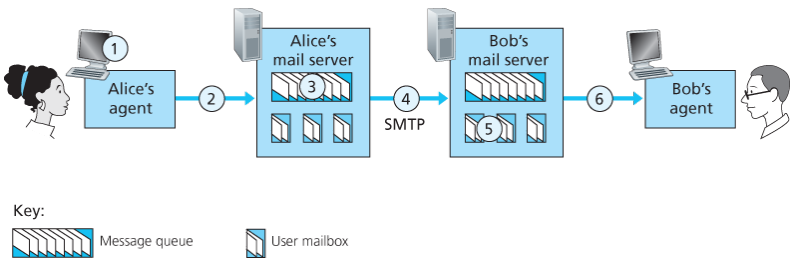
假设Alice打算向Bob发送一封电子邮件,其步骤如下:
- Alice调用她的用户代理,提供Bob的邮件地址,撰写完邮件后,指示用户代理发送该报文。
- Alice的用户代理把报文发送给她的邮件服务器,并将报文放在报文队列中。
- 运行在Alice邮件服务器上的SMTP客户端发现了报文队列中的这个报文,它就创建一个与Bob邮件服务器上SMTP服务器通信的TCP连接。
- 在经过初始SMTP握手(??)之后,SMTP客户端通过TCP连接,发送Alice的报文。
- Bob邮件服务器上的SMTP服务端接收该报文,并将其放入Bob的用户邮箱中。
- 在Bob方便的时候,他调用用户代理阅读该报文。
如下图所示:
其中,SMTP通信的过程为:
- SMTP客户端与SMTP服务器的25端口建立一个TCP连接。
- 如果服务器没有开机,客户端会在稍后继续尝试。
- 一旦连接建立,SMTP的客户端和服务端会在传输信息前,先互相介绍,即握手阶段。握手时,SMTP客户端会指示发送方的邮件地址和接收方的邮件地址。
- 彼此介绍后,客户发送该报文。
这里,解释一下,为什么不直接从用户代理将邮件报文发送到Bob的邮件服务器呢? 因为,用户代理运行在用户主机上,不可能总是尝试与一台服务器(如果服务器一直已关机的话)建立连接。
假设客户端(C)主机名为crepes.fr,服务器(S)主机名为hamburger.edu。一旦TCP连接创建,通信内容如下:

其中,全大写单词(HELO,MAIL FROM, RCPT TO, DATA, QUIT)都为“关键字”。可以看出,SMTP协议的通信规则相比HTTP简单很多。
而与HTTP不同的还在于,SMTP是推协议,HTTP是拉协议。
3.2. 邮件报文格式
注意:这里的报文是,整个邮件报文,并不是SMTP客户端与服务端通信时的信息单位。
邮件报文格式如下:
- 首部:
From:首部行,必须To:首部行,必须Subject:首部行,可选- 其它可选首部行
- 报文体,ASCII码格式
3.3. 邮件访问协议
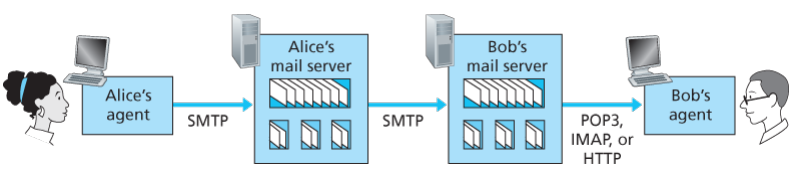
一旦SMTP将邮件报文从Alice的邮件服务器交付给Bob的邮件服务器,该报文就被放入了Bob的邮箱中。那Bob是如何来阅读这封邮件的呢?
- 从前,Bob是通过登录到服务器主机,并在主机上运行邮件阅读程序来阅读他的电子邮件的。
- 现在,邮件访问采用 客户-服务器 体系,即通过用户端系统上运行的客户程序来阅读电子邮件。
在Alice发送邮件给Bob的整个过程中,Alice用户代理使用SMTP将邮件报文推入她的邮件服务器,她的邮件服务器再用SMTP将邮件报文推向Bob的邮件服务器。
那么,问题来了,Bob是如何通过用户代理获取他邮件服务器上的邮件的呢?必须知道的是,肯定不能使用SMTP协议,因为这是一个“推协议”。
而这个问题,可以用邮件访问协议来解决。流行的邮件访问协议有三种:
- POP3
- IMAP
- HTTP
3.3.1. POP3
POP3(Post Office Protocol–Version 3),又称第三版的邮局协议,由[RFC 1939]定义。
用户代理与服务器的110端口建立TCP连接后,就开始POP3的工作,主要包括三个阶段:
- 特许阶段:用户代理发送(以明文形式)用户名和口令用以鉴别用户。
- 事务处理阶段:用户代理取回报文,并对报文进行下载、标记删除、取消删除标记、获取邮件统计信息等操作。
- 更新阶段:用户代理发送结束命令,会话结束,邮件服务器删除被标记为删除的报文。
POP3存在的缺陷:用户可以下载邮件到本地,并创建文件夹进行管理。但是,POP3协议没有给用户提供任何创建远程文件夹,并为报文指派文件夹的方法。所以,每到一台新机器上,用户都得重新创建文件夹进行管理,这样很麻烦。
3.3.2. IMAP
IMAP(Internet Mail Access Protocol),又称因特网邮件访问协议,由[RFC 3501]定义。
相对POP3,IMAP有以下改进:
- IMAP服务器会把每个邮件报文与一个文件夹关联起来。允许用户创建文件夹,并移动邮件,用户可以在文件夹中阅读、删除邮件,还提供查询邮件的功能。
- 允许用户代理获取邮件报文的一部分。用户可能并不像取回他邮箱中的所有邮件,尤其是包含音频或视频的大邮件。
3.3.3. HTTP
今天,许多邮箱提供商(如QQ邮箱),或者大学、公司,都提供了基于Web的电子邮件。
用户代理就是普通的浏览器。用户使用HTTP从邮件服务器中获取邮件,同时,用户也使用HTTP将邮件发送到邮件服务器。但邮件服务器之间,仍然使用SMTP进行通信。
4. 目录服务与 DNS 协议
众所周知,因特网上的主机,由IP地址标识。所谓IP地址,是由四个0~255内的十进制数组成,通过.分隔,如:192.168.0.1。
但是,对于人类来说,要记住这么一串无特征的数字,是十分困难的。于是,出现了另一种标识主机的方法——**域名/主机名(hostname)**,如:www.baidu.com。
那么,如何将主机名映射到对应的IP地址呢?这就是域名系统(Domain Name System, DNS) 的主要任务了。
DNS包括两部分:
- 由分层的DNS服务器实现的分布式数据库;
- 属于应用层的DNS协议,它运行在UDP之上,发送和接受的报文都经过53号端口。
4.1. Services Provided by DNS(DNS 提供的服务)
DNS通常是由其它应用层协议所使用的,包括HTTP、SMTP和FTP等协议。
DNS所提供的服务,主要包括:
将主机名(域名)解析为IP地址。例如,用户主机需要向
www.example.com服务器发送HTTP请求,它必须先获得www.example.com的IP地址,其过程如下:- 用户主机上运行着DNS应用的客户端。
- 浏览器从URL中抽取主机名
www.example.com,传给DNS应用的客户端。 - DNS客户向DNS服务器发送一个包含主机名的请求。
- DNS客户端最终会收到一份回答报文,其中包含主机对应的IP地址。
- 一旦浏览器接收到IP地址,它就能向位于该IP地址80端口的HTTP服务器进程发起一个TCP连接。
**主机别名(host aliasing)。例如,一台名为
relay1.west-coast.enterprise.com的主机,可能还有两个别名:enterprise.com和www.enterprise.com。此时,relay1.west-coast.enterprise.com则被称为规范主机名(canonical hostname)**。应用程序调用DNS可以获得主机别名对应的规范主机名,和主机IP地址。**邮件服务器别名(mail server aliasing)**。电子邮件应用程序可以调用DNS,解析对应的主机名(比如:
@qq.com中的qq.com),以获得该主机的规范主机名和IP地址。负载分配(load distribution)。繁忙的站点(比如:
taobao.com)通常拥有多台服务器,每个都有着不同的IP地址。在DNS服务器中,一个IP地址集合与同一个规范主机名相联系,在每次回答中,循环响应这些IP地址。从而实现负载分配。
4.2. Overview of How DNS Works(DNS 工作机制概述)
DNS是一个在因特网上实现分布式数据库的优秀范例。
4.2.1. A Distributed, Hierarchical Database(分布式、层次数据库)
按层次分,可分为三类DNS服务器:
**根DNS服务器(Root DNS Servers)**。全球有400多个根服务器
[Root Servers 2016],它会提供TLD服务器的IP地址。
**顶级域DNS服务器(top-level domain, TLD)**。对于每个顶级域(如:com、org、net、edu等)和国家级的顶级域(如:uk、fr、jp等),都有TLD服务器,它们会提供权威DNS服务器的IP地址。
**权威DNS服务器(authoritative DNS servers)**。一个权威DNS服务器中,收藏了一个主域名及其子域名的主机IP地址,如:
qq.com的权威服务器知道mail.qq.com、lol.qq.com、music.qq.com等主机的IP地址。一个组织机构可以实现自己的权威服务器以保存记录;也可以将自己的记录储存在服务提供商的一个权威服务器中。
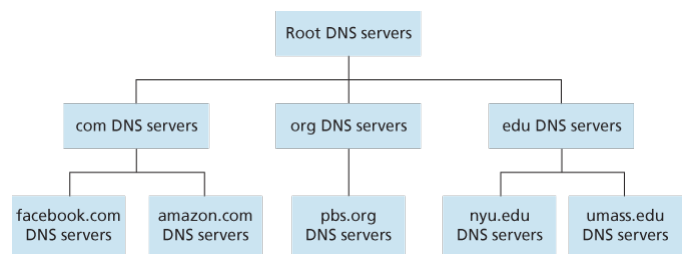
除了三大DNS服务器,还有另一类重要的DNS服务器——**本地DNS服务器(local DNS server)**。每个ISP都有一台或多台本地DNS服务器,它负责将DNS转发出去。
DNS查询通常有两种方式:
- **迭代查询(iterative queries)**。假设主机
cse.nyu.edu想知道主机gaia.cs.umass.edu的IP地址,其过程如图:
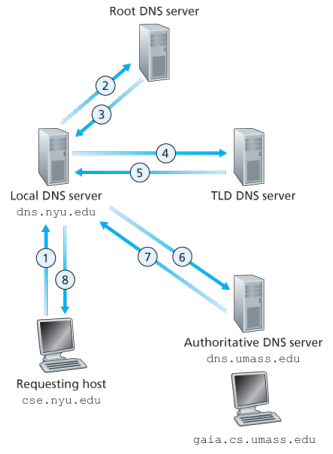
- 递归查询(recursive queries)
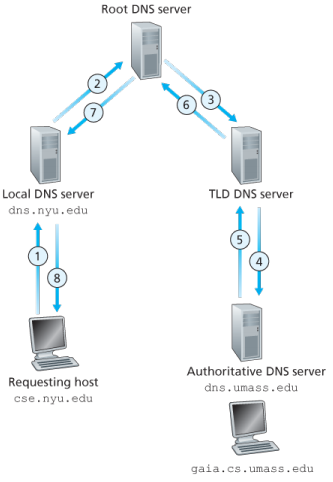
4.2.2. DNS Caching(DNS 缓存)
通常本地DNS服务器会缓存查询过的DNS记录。
缓存的好处就不多说了。
4.3. DNS Records and Messages(DNS 记录和报文)
4.3.1. DNS 记录
DNS服务器存储了**资源记录(Rescourece Record, RR)**,它提供了主机名到IP地址的映射,每个DNS回答报文包含了一条或多条资源记录。
资源记录是一个如下的4元组:
1 | (Name, Value, Type, TTL) |
TLL,该记录的生存时间,决定了资源记录应当从缓存中删除的时间。Type,记录类型,它决定了Name和Value的值:Type = A,则Name是主机名,Value是主机名对应的IP地址。例如:(relay.example.com, 145.37.93.126, A, xxx)。Type = NS,则Name是一个主域名(如:qq.com),而Value是该域的权威DNS服务器的主机名。例如:(foo.com, dns.foo.com, NS, xxx),它通常与(dns.foo.com, 128.119.43.111, A, xxx)一起返回。Type = CNAME,则Name是一个别名,Value是对应的规范主机名。例如:(foo.com, relay1.bar.foo.com, CNAME, xxx)。Type = MX,Name是一个别名,指向邮件服务器,Value是对应的规范主机名。例如:(foo.com, mail.bar.foo.com, MX, xxx)。
(以上所有主机名和IP地址都是瞎编的。。。)
4.3.2. DNS 报文
DNS 有查询和回答报文,且两种报文格式相同,如下:
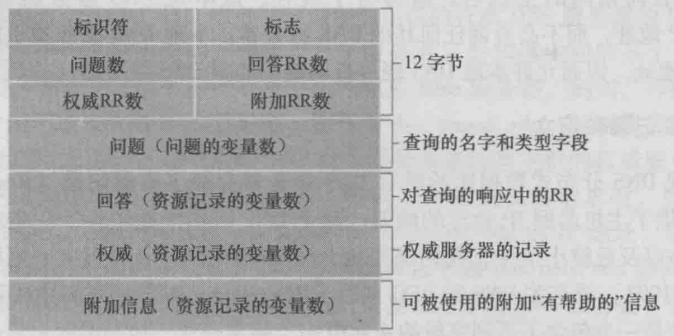
首部区域,前12个字节:
- 标识符,用于标识该查询,会被复制到对应查询的回答报文中,以便用户匹配发送的请求和接受的回答(我猜是因为UDP的特殊性)。
- 标志,包含若干标志位:
- “查询/回答” 标志位,1bit,指出是查询报文(0)还是回答报文(1)。
- “权威” 标志位,1bit,当某DNS服务器是所请求名字的权威DNS服务器时,置1。
- “希望递归” 标志位,1bit,如果客户在该DNS服务器没有该记录时希望它执行递归查询,置1。
- “递归可用” 标志位,1bit,如果该DNS服务器支持递归查询,在它的回答报文中,会被置1。
- 问题数、回答RR数、权威RR数、附加RR数,指出首部后的4类数据区域中的变量数。
问题区域,包含正在进行的查询信息:
- 名字字段,正在被查询的主机名。
- 类型字段,指出正在被查询的问题类型,如:A、MX。
回答区域,包含了对最初请求的名字的资源记录,可以包含多条RR。
权威区域,包含了其它权威服务器的记录。
附加区域,包含了其它有帮助的信息。例如,一个MX请求的回答报文的回答区域中,包含了一条提供邮件服务器规范主机名的资源记录;而附加区域中,则包含了一条提供该规范主机名的IP地址的A类型RR。
4.3.3. 在 DNS 数据库中插入你的记录
首先,
你需要有钱你需要在注册登记机构注册域名,你也可以在阿里云、腾讯云中购买域名,它们会帮你注册。你需要向机构提供你的权威DNS服务器的主机名和IP地址,机构会将一个类型NS和一个类型A的记录插入TLD服务器中,如:
1
2(foo.com, dns.foo.com, NS, xxx)
(dns.foo.com, 128.119.43.111, A, xxx)在你的权威DNS服务器中插入你需要的记录。比如:
1
2(www.foo.com, 128.119.43.231, A, xxx)
(study.foo.com, 128.119.43.245, A, xxx)如果你
没钱搭建没有权威服务器,你也可以跳过2、3步,将记录存储在服务提供商的权威服务器中,如阿里云、腾讯云提供的域名解析。
5. Peer-to-Peer File Distribution(P2P 文件分发)
5.1. P2P 体系与客户-服务器体系对比
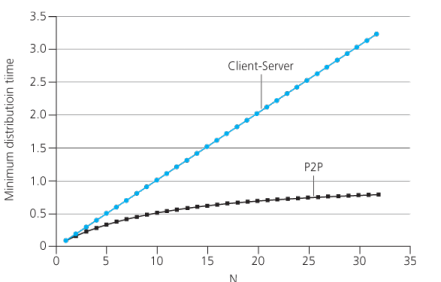
N-对等方数量
由图可知,P2P体系结构最小分发时间总是小于客户-服务器体系结构。
5.2. BitTorrent
到2016年止,最为流行的P2P文件分发协议是BitTorrent。
参与一个特定文件分发的所有对等方的集合被称为一个**洪流(torrent),在一个洪流中的对等方彼此下载等长度的文件块(chunk)**,典型的长度为256KB。
当一个对等方首次加入一个洪流时,他没有块。随着时间流逝,它累积了越来越多的块。当它下载块时,也为其它对等方上载了多个块。一旦某个对等方获得了整个文件,他也许会自私地离开,也许会无私地留在洪流中向其它对等方上载块。
因为BitTorrent是一个复杂的协议,所以我们将仅描述它最重要的机制:
- 每个洪流具有一个基础设施节点,称为**追踪器(tracker)**。当一个对等方加入某个洪流时,它向追踪器注册自己,并周期性地通知追踪器它仍在该洪流中。
- 当一个新的对等方A加入洪流时,追踪器会随机地从参与对等方的集合中选择对等方的一个子集,并将这些对等方的IP地址发送给A。A试图与该IP地址列表上所有的对等方创建并行的TCP连接。我们称所有与A创建TCP连接的对等方为邻近对等方,邻近对等方会随着时间而变化。
- 任意时刻,每个对等方将具有该文件的块的子集,并且不同对等方具有不同的子集。A周期性地询问每个邻近对等方它们所具有的块列表。有了这些信息,A将对当前还没有的块发出请求。
任何时刻,A将具有块的子集,并知道它的邻居具有哪些块。利用这些信息,A将做出两个重要决定:1.她应当从她的邻居请求哪些块呢?2.应当向哪些向她请求块的邻居发送块?在决定过程中,A将使用两种技术:
**最稀缺优先(rarest first)**:针对她没有的块,最稀缺块是指那些在她邻居中副本数量最少的块,她会优先请求那些最稀缺块。目的是均衡每个块在洪流中的副本数量。
对换算法:A根据当前能够以最高速率向她提供数据的邻居,给出其优先权。以最高速率流入的4个邻居,被称为疏通(unchoked)。每过30秒,她要随机选择另一个邻居B,并向其发送块。因为A正在向B发送数据,她可能成为B前4位上载者之一。这样,B将开始向A发送数据,如果B发送速率够高,B也将成为A的前4位上载者。换而言之,每过30秒A将随机地选择一名新的对换伴侣,并与其对换。如果这两个对等方都满足彼此,它们将对方放入前4位列表中,并继续与对方对换,直到它们发现更好的伴侣为止。
6. Video Streaming and Content Distribution Networks(视频流和 CDN)
6.1. Internet Video
视频的一个重要特征是它能够被压缩,因此可以用比特率来衡量视频质量。
比特率越高,图像质量越好。其实,比特率就是我们看片看视频时,选择的视频清晰度:360P、720P、1080P。
6.2. HTTP流 和 DASH
在HTTP流中,视频只是存储在HTTP服务器中的一个普通文件,有特定的URL。用户通过HTTP请求获取视频文件,视频的字节被收集在客户应用缓存中。一旦该缓存中的字节数量超过预先设定的门限,用户应用程序就开始播放。同时,应用程序周期性地从缓存中抓取帧,解压并展现。
HTTP有一个严重缺陷:所有客户收到相同编码的视频。
为此,人们又研发了经HTTP的动态适应性流(Dynamic Adaptive Streaming over HTTP, DASH)。在DASH中,视频编码为几个不同版本,其中每个版本具有不同的比特率。客户动态地请求来自不同版本且长度为几秒地视频段数据块。
DASH实现:HTTP服务器上会有一个**告示文件(manifest file)**,为每个版本提供一个 URL 及其比特率。客户先请求告示文件,然后再通过 HTTP GET 请求报文中指定URL和字节范围,一次选择一个块。在下载的同时,用户也测量接收带宽并运行一个速率决定算法来选择下次请求的块。
6.3. CDN / 内容分发网
**内容分发网(Content Distribution Network, CDN)**,是一个构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
说简单点,CDN就是缓存。
CDN可以是专用CDN,即由内容提供商自己所拥有;也可以是第三方CDN。
CDN通常采用两种不同的服务器安置原则:
深入(Enter Deep)。该原则通过在全球的接入ISP中部署服务器集群来深入到ISP的接入网中。但因为这种高分布式设计,维护和管理集群成为一大问题。
**邀请做客(Bring Home)**。通过在少量关键位置建造大集群,以此邀请ISP来做客。被许多CDN公司所采用。
6.3.1. CDN 实现
大多数CDN利用DNS来截获和重定向请求。例如:
- 用户想观看一个URL为
video.example.com/V123456的视频时,用户主机发送一个对于video.example.com的DNS请求。 - 用户的本地DNS服务器,将该DNS请求转发到
example的权威服务器。权威服务器看到主机名中的video前缀,则将DNS移交给第三方CDN,它将返回一个第三方CDN域的主机名,如:kingcdn.com。 - 用户的本地DNS服务器则发送第二个DNS请求,此时是对
kingcdn.com的DNS请求。 - 此时,第三方kingcdn的DNS系统,会指定一个CDN服务器,用户能够从这台服务器接收到它的内容。
- 本地DNS服务器向用户返回CDN服务器的IP地址。
- 用户获取IP地址后,向对应CDN服务器获取所需视频。
6.3.2. Cluster Selection Strategies(集群选择策略)
集群选择策略,是动态地将客户定向到CDN中的某个服务器集群或数据中心的机制,即为用户选择一个相对较近的CDN服务器集群。
一种简单的策略,就是指派地理上最邻近的集群。但问题是忽略了时延和带宽。
因而,CDN需要对集群和用户之间的时延和丢包执行周期性的实时测量。但问题是许多本地DNS服务器不会响应这些探测。
7. Socket Programming: Creating Network Applications(套接字编程)
7.1. UDP
UDP客户端:
1 | from socket import * |
UDP服务端:
1 | from socket import * |
7.2. TCP
TCP客户端:
1 | from socket import * |
TCP服务端:
1 | from socket import * |