分布式之GFS
0. 前言
2000年前后,随着互联网的飞速发展,单机的存储和计算能力早已达到瓶颈,急需通过增加机器数量来提高整体性能。但是,1+1并不大于2,机器数量的增加带来了许多新的问题:网络延迟、机器宕机、数据不一致等等。正是为了解决这些问题,Google在2003-2006年间先后发表了3篇论文《GFS》、《MapReduce》、《Bigtable》,分别解决了大规模数据的存储(非结构化)、计算、索引(结构化数据/数据库),这三篇也被称为Google三驾马车,鉴定了分布式大数据时代的基础。后来的开源项目Hadoop中,HDFS参考了《GFS》,MapReduce参考了《MapReduce》,HBase参考了《Bigtable》。
GFS首先被提出,它在大规模分散的机器上,实现了类似Linux文件系统的分布式存储系统。单台机器读写数据的性能有限,对于数亿GB的海量,肯定不能存放在单台机器上,而应将数据分割存储到多台机器上。同时,还需考虑机器宕机、磁盘损坏的问题,对同一份数据应做多个备份。如此又会出现许多新问题:如何在多台机器中找到用户想要的数据?如何保证系统在部分机器失效的情况下仍能正常运行?如何保证多个备份数据的一致?如何保证较高的读写性能?这些问题都将GFS中得到解决。
1. 设计假设
建立在大量廉价的机器上,机器经常会失效,因此需要不停地监控-容错-恢复。
适用于存储大文件(MB或GB)。
大的流式顺序读,小的随机读。顺序读取连续的大批量数据(MB),只在某个位置偏移几KB范围内的随机读取。
一旦写入,就很少被修改。
同一时刻,同一文件,可能被多个客户端并发地追加数据,因此需要保证最小同步操作(追加)的原子性(Atomicity with minimal synchronization overhead is essential)。
高持久的带宽(批量处理数据)比低延迟(单个读写操作的响应时间)更加重要。
2. 架构
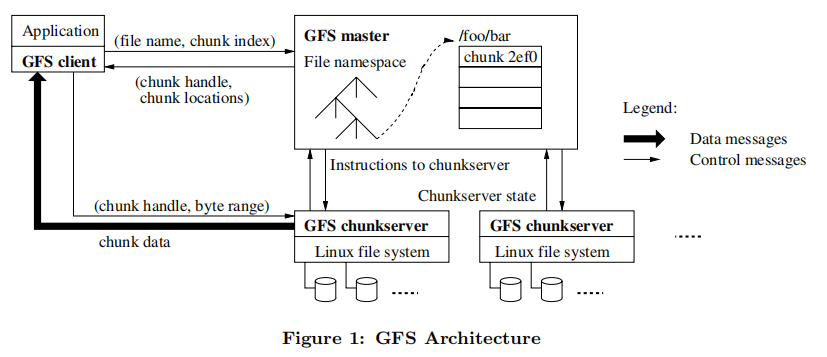
GFS集群中包含1个master和多个chunkserver。
GFS中,每个文件被划分成固定大小的chunk(默认64MB),每个chunk都有一个全局唯一的64bit的标识(chunk handle, 句柄),每个chunk被备份到多个chunkserver(默认3个)。
master只保存元数据,比如:文件命名空间、文件对应每个chunk的chunk handle、每个chunk所在的chunkserver等等。master和chunkserver通过周期性的心跳进行通信。
chunkserver负责保存chunk数据,它会将chunk以Linux文件的形式存储在本地。客户端可通过chunk handle和字节范围(0~64MB)来获取chunk内数据。
master元数据
master主要存储3类元数据:
文件命名空间(namespace)。
文件和chunk的映射关系:file name -> array of chunk handles。每个文件都对应一个chunk handle数组,数组第i个元素是文件中第i个chunk的标识(handle)。
每个chunk对应的相关信息:chunk handle ->
存储位置list of chunkservers,1个chunk会被复制并存储到多个chunkserver上(备份,用于容错)。
版本号version,用于判断是否最新。
主副本primary,用于写操作。
租约lease,用于写操作。
上述元数据都会存在于内存中,以此提高操作效率。
前2个元数据的变更操作,会以日志的形式记录,并持久化保存到本地磁盘,同时备份到远程机器上(容错)。当master重启时,会重放日志来恢复关键信息。为了缩短恢复时间,master会在日志超过一定长度时,设置一个**检查点(checkpoints)**。恢复时,只需要最新的检查点和之后的日志。checkpoint是一个压缩的类B-Tree结构,可以被直接映射到内存中并用于namespace的查找。
chunk的存储位置并不会持久化保存,而是在master启动后向每个chunkserver询问得知。master会通过周期性心跳检测与chunkserver通信,保证自己的chunk信息是最新的。为什么不持久化保存chunk的位置信息?因为在数百台机器的集群中,chunkserver加入或离开、重启、宕机等情况经常发生,chunk的位置信息需要经常变更、并不稳定,持久化没有太大意义。
但chunk版本号需要持久化,master需要通过chunk版本号判断chunkserver的chunk副本是不是最新的。为什么不向chunkserver询问chunk的版本号,然后取其中最大值呢?因为master询问时,持有最新chunk副本的chunkserver可能出现宕机等意外情况,导致master将过时的副本当作最新版本。master只会返回包含最新chunk的chunkserver,如果所有chunkserver都不包含该chunk的最新版本,master会让客户端等待或返回错误。
3. 系统交互
读文件
如图1所示,一次简单的读文件过程如下:
客户端根据要读取的文件名和偏移量,计算出chunk index,比如:读取文件第65MB至第80MB间的数据,其所在的chunk index为65MB/64MB = 1。
客户端向master发生文件名和chunk index,master会返回chunk handle和chunk所在的chunk server列表。
客户端向其中一个chunkserver发送请求,指定chunk handle和读取的字节范围,chunkserver返回相应的数据。
写文件
写文件,包括对文件内容的修改和追加,每个写的变更操作都需要在对应chunk的所有副本上执行。
对于一组变更操作,GFS通过租约(leases)来保证多个副本间变更顺序的一致性。master会向其中一个副本授予chunk租约,这个副本被称为主副本(primary)。主副本会对该chunk的所有变更选择一个顺序,然后所有的副本就会按照这个顺序去执行这些变更。租约的持续时间为60s,主副本可以向master请求延长租约。master可以在租约到期前撤销授权。若master与主副本失去通信,并不需要立即选择新的主副本(可能只是暂时的网络阻塞),它可以在旧租约过期后,安全地授权租约给另一个副本(避免同时出现两个主副本)。 授权和请求都伴随chunkserver和master间的心跳信息一起发送。
一次写操作过程如下:
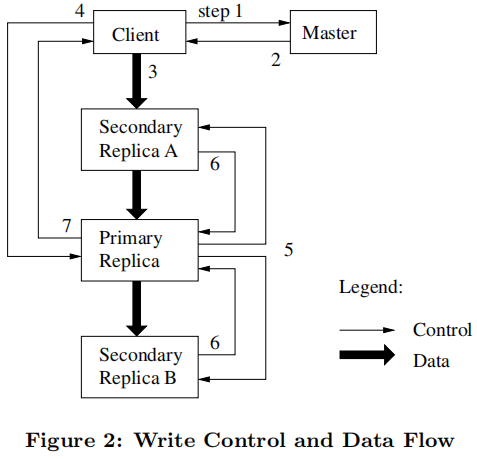
客户端会请求master所有副本位置,以及哪一个chunkserver持有当前的租约(谁是主副本)。如果没有副本持有租约,master会选一个副本授权租约给它(即设为主副本)。
master返回该主副本的标识(handle)和所有副本的位置信息,客户端缓存这些数据用于未来的变更。只有当主副本没有响应,或者发现租约已经到期了,客户端才会和master联系。
客户端向所有副本对应的chunkserver推送数据,可按任意顺序。chunkserver会缓存这些数据,直到被使用或过期。GFS通过分离控制流和数据流,将重要的数据流基于网络拓扑来进行调度,而不用考虑哪一个是主副本,从而提高性能。
一旦所有副本都确定收到数据,客户端会向主副本发送一个写请求,该请求标识了之前推送给所有副本的数据。然后,主副本会给它接收到的所有变更(可能来自于多个客户端)分配连续的序列号,并按照序列号将变更应用到本地的副本上。
主副本向其它副本发送写请求,每个副本都按照主副本规定的顺序应用这些变更。
其它副本变更完成后,会向主副本返回成功。
主副本再向客户端返回成功。任何副本碰到错误,都会返回给客户端。出现错误时,变更可能已经在主副本和部分副本上执行成功了(部分执行成功的变更会撤销吗?不会!)。若返回错误,客户端会重试这些变更,它会先重试3-7步骤,如果不行则从头重试写操作。
如果一个写操作数据量很大或跨chunk边界,GFS客户端会将其分割为多个写操作。
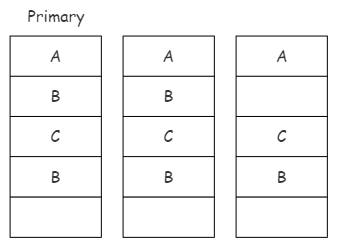
GFS并不保证强一致性:如果写操作发生错误,GFS并不会撤销已成功执行的副本中的变更,各副本可能不一致。如下图,对同一个文件,客户端1请求追加数据A,客户端2请求追加数据B,客户端3请求追加数据C,请求同时达到。primary将这些变更排序后发给其它副本,其中一个副本在执行追加数据B时发生错误,错误返回给客户端2。客户端2重新发送写请求,此次请求成功。最终,导致各副本间状态并不一致。
GFS分离控制流和数据流,以更好地利用网络带宽。当客户端向chunk所在的chunkserver节点推送数据时,它会先发给距离最近的。假设客户端要推送数据到chunkserver S1~S4,它先推送给最近的机器S1,然后S1推送给最近的S2,类似的S2推送给S3或者S4。
GFS提供原子性的append操作,称作record append。多个客户端可以并发地append,而不需要进行复杂的同步操作,比如分布式锁。record append也是一种变更操作,其过程与上述过程基本类似,只是主副本会先检查append数据是否超过最后一个chunk大小,若超过,它就将该chunk填充到最大值,然后告知客户端剩余操作应该在下一个chunk上重试。
快照
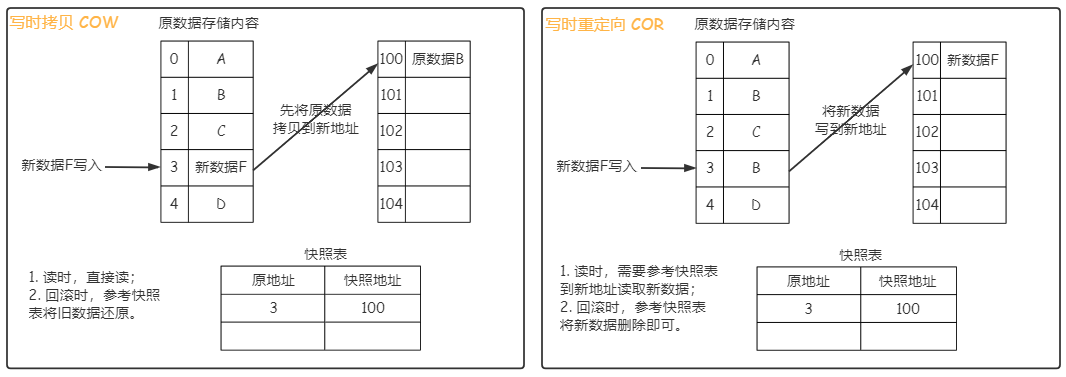
快照是一种完全可用拷贝,但并不是备份那样的完整拷贝。什么意思呢?备份是将全部数据完整拷贝到另一个副本上,而快照是在原数据的基础上,只将修改的新数据另存,而原数据保持不变。由于快照共享原数据,只需额外保存新数据,因此所占空间远小于备份,但容错性也更低。实现快照的方式有两种:**写时拷贝(COW, Copy On Write)、写时重定向(ROW, Redirect On Write)**。写时拷贝:在写数据时,将原数据拷贝到另一处,再将新数据写入。写重定向:在写数据时,直接将新数据写到另一处。
GFS提供快照功能,并采用写时拷贝来实现。当master收到要对某个文件创建快照的请求时,它会撤销该文件对应所有chunk的租约,并进行一些配置。当客户端在快照请求后第一次对某个chunk C进行写操作时,master会选择一个新的chunk C’,然后让所有拥有chunk C的chunkserver都创建chunk C’,并将chunk C数据拷贝到chunk C’,接着客户端就可以正常进行写操作。
5. Master操作
namespace管理
不同于传统的文件系统,GFS不存在目录数据结构,并不能列出一个目录下的所有文件,也不提供别名。GFS只将文件的全路径作为文件的key,并通过前缀压缩高效地存储在内存中,namespace树(前缀压缩树)中每个节点(一个文件或目录)都有一个读写锁。
master中操作需要一系列锁来配合,比如:如果要操作/d1/d2/…/dn/leaf,那么他就需要从/d1、/d1/d2、… 到/d1/d2/…/dn这些目录的读锁,以及/d1/d2/…/dn/leaf全路径的读锁或者写锁。文件写操作并不需要父级目录的写锁,是因为我们没有“目录”或者类似于inode的数据结构,使用读锁已经能够有效防止目录被删除。
这种锁模式的一个好处就是它允许对同一个目录进行并发的变更操作。比如多个文件创建操作可以并发地在同一个目录里面执行。每个操作需要一个目录的读锁和一个文件名的写锁。在目录上的读锁可以防止目录被删除,重命名或者快照。针对文件的写锁可以保证相同文件名的只会被创建一次。
副本放置
chunk副本的放置策略:最大化数据可靠性和可用性,最小化网络带宽的使用。因此,GFS会把副本分散到不同位置的集群上。
创建chunk副本
创建chunk副本的情况有3种:chunk的初次创建、重备份、重平衡。
初次创建chunk时,master会考虑以下因素来放置chunk副本:磁盘使用率较低的chunkserver;最近创建chunk次数较少的chunkserver;不同位置集群中的chunkserver。
一旦可用的chunk备份数量低于用户指定的数量(chunkserver失效等情况),master就需要重新备份一个chunk。
master会周期性地对副本进行重平衡:检查副本分布,将副本移动到磁盘使用率较低的chunkserver上。
垃圾回收
一个文件被删除后,master会将删除操作记录到日志中,但不会立即释放资源,该删除的文件只是被重命名为一个包含了删除时间戳的隐藏文件名。当master对namespace进行常规扫描时,如果发现某个隐藏文件已存在3天以上,就会移除这个文件。在这之前,可以通过重命名为正常名字来撤销删除操作。当从namespace中移除文件后,文件相应的chunk也就孤立了,master还会将孤立的chunk从元数据中移除。
当chunkserver与master心跳通信时,chunkserver会向master报告一个chunk集合,master会标识出其中已经不存在的chunk并返回,然后chunkserver就可以自由地删除这些chunk副本。
这种垃圾回收方式的好处是简单可靠,master不需要准确知道哪些chunkserver有这些chunk,哪些没有。同时,伴随在namespace常规扫描、chunkserver心跳等操作中,减少额外开销。但坏处是不能及时清理,占用磁盘。
过期副本检测
当一个chunkserver停机或者失效,它拥有的chunk副本将不能进行新的变更操作,导致chunk副本过期。对于每个chunk,master通过版本号来区分最新还是过期的副本。
一旦master对一个chunk授权一个新的租约,就会增加该chunk的版本号,并通知chunk副本所在的所有chunkserver更新,master和chunkserver都会持久化地记录这个副本的新版本号。这发生在客户端写数据之前。
如果一个chunkserver失效,它将收不到更新通知,它对应的chunk副本版本号也不会更新。当它重新启动时,会向master报告它的chunk集合和版本号,master就能检测到这个过期副本。master会通过周期性的垃圾回收来移除这些过期的副本。
当master发现有chunkserver版本号大于它保存的,它就会更新自己的版本号。
读数据时,若请求过期副本,会返回不存在。写数据时,master会将chunk的版本号一同发给客户端,客户端在执行操作前会验证版本号。
6. 容错和诊断
高可用
GFS使用两个简单有效的策略来保证高可用:快速恢复和备份。
master和chunkserver无论如何被终止,都会在几秒内恢复状态并启动。
chunk会被备份到多个chunkserver上。
master的操作日志和检查点也会被备份到多台机器上。一个对master状态的变更,只有在日志记录已经完全写到本地磁盘和其他所有的副本之后,才会认为是提交了。如果master所在的机器或者磁盘失败了,在GFS外部的一个监控基础设施就会在别的地方,通过备份的操作日志重新开启一个新的master进程。
在主master已经挂掉了的情况下,“影子”master依然可以为这个文件系统提供只读访问。他们是影子,并不是镜像,所以他们可能会比主master稍微落后一些,通常是几秒。对于那些不经常变更文件或者应用程序不介意获取到的是有点旧的结果,这提高了读的可用性。影子master为了保证自身的实时性,一个影子master会读取一个不断增长的操作日志的副本,然后将这些操作序列应用在自己的数据结构上。
数据完整性
每个chunkserver使用校验和来检测数据是否被破坏。由于GFS不保证强一致性,不同chunkserver上的chunk副本可能不一致,chunkserver可以通过其它chunk副本来恢复数据,但需要自己维持校验和来独立地验证。一个chunk被分割成64KB大小的块,每个块都有32bit的校验和,这些校验和会被持久化保存。
读操作时,chunkserver会验证读取的数据块的校验和,当校验和不一致时,chunkserver会返回错误。
对于写操作,如果是append操作,会计算并保存新增加块的校验和。如果是覆盖原有内容,会先验证原有内容第一块和最后一个块,然后再执行写操作,最后重新计算并保存被覆盖块的校验和。
7. 个人总结
GFS对于大型的分布式文件存储有着革命性影响,虽然GFS的具体实现并未开源,许多细节也没有在论文中详细讲解,但它的许多设计理念依旧值得学习,比如:
结合具体场景进行取舍。在文件存储系统中,并不一定要保证强一致性,不如牺牲部分一致性来提高性能。
将数据流和控制流分离,从而对数据流进行更好的优化。
通过租约将写操作交给主副本所在的chunkserver管控,分摊master压力。