分布式之Spanner
0. 前言
Spanner由谷歌2012年的论文《Spanner: Google’s Globally-Distributed Database》提出,是谷歌的一个全球级别的分布式数据库。它管理着全球成百上千个数据中心,数百万个服务器,将数万亿数据分片存储到这些服务器上。同时,它支持以下特性:
支持高可用(数据的备份和恢复)。数据可以有多个备份副本,并且可以灵活、细粒度地配置:副本数量、副本所在的数据中心等。副本甚至可以跨国家存储,即使面临大范围自然灾害,数据依旧可用。
同时,Spanner保证这些副本的外部一致性(谷歌创造出来的一种一致性)。
支持广域的分布式事务,对于涉及不同数据中心的事务,也能保证ACID特性。
Spanner如何保证这些特性呢?具体内容请看下文。
1. 架构
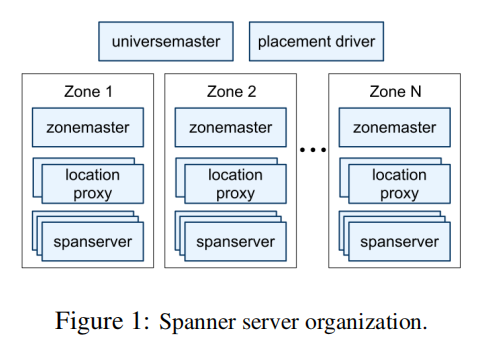
Spanner的架构如上图所示,Spanner管理着多个Zone,每个Zone管理着成百上千个spanserver,一个数据中心可能有一个或多个Zone。为了更好地理解,我们做如下假设。
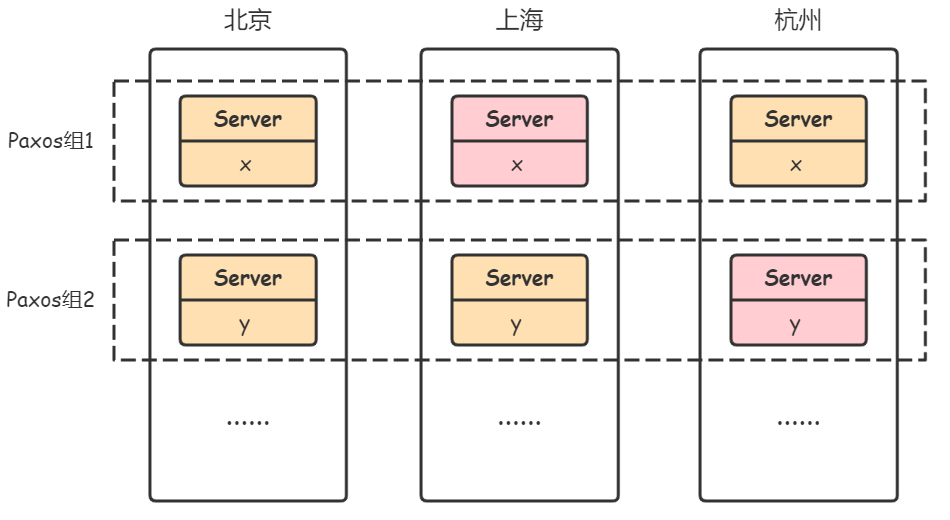
假设,Spanner在北京、上海、杭州各有一个数据中心(一个数据中心只有一个Zone),每个数据中心都有数台服务器(spanserver)。某个应用将数据通过Spanner进行分片存储:在北京的数据中心有2台服务器,1台存储着a-m的数据,1台存储着n-z的数据。不同分片服务器处理不同分片的请求,提高系统并行吞吐量。同时,在上海的数据中心,也有1台存储着a-m数据的副本,1台存储着n-z数据的副本;杭州同理。这些不同数据中心的副本,相互保持一致。如此,每个数据中心的副本都可以快速地为当地的用户进行服务,且彼此之间保证高可用/容错。
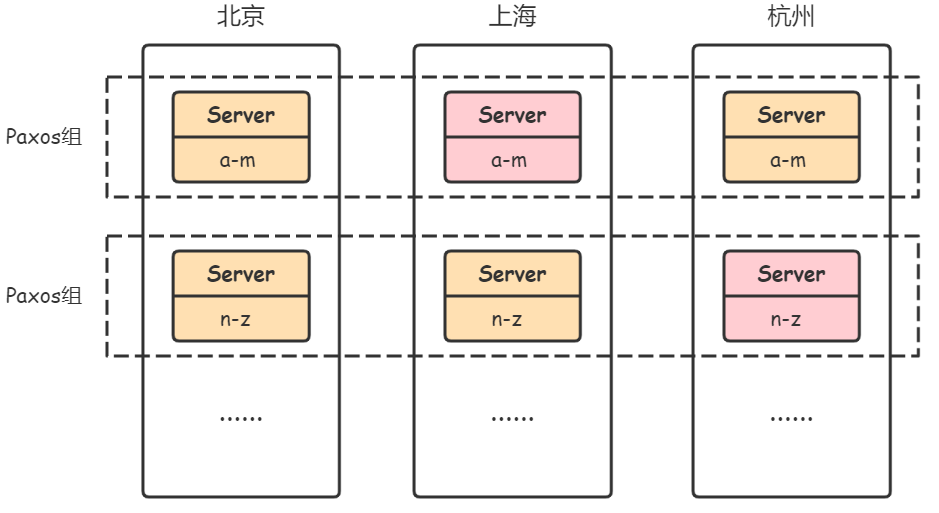
Spanner通过Paxos算法保证不同数据中心副本之间的一致性。因此,不同数据中心存放相同数据副本的服务器可看作一个Paxos组。每个Paxos组中,会有一个leader(比如上图中的粉红色Server),它负责将状态变更同步到其它副本,同时它也负责事务操作。不同Paxos组的leader之间也会相互合作,完成跨数据分片(跨Paxos组)的分布式事务,其中一个leader会被选为事务协调者(coordinator leader)。
面临的挑战:
将副本分散在相隔较远的数据中心,其好处是能为当地用户快速响应,同时能更好地抵御突发情况(比如某个数据中心突然断电)。但坏处在于:leader与follower的通信成本增高;另外,Paxos只需要状态变更同步到超半数副本即可,因此较远的数据中心的副本可能并不是最新的。
当事务只对一个分片内的数据做读写时,比如修改数据b的值,它只需要请求分片(a-m)所在Paxos组的leader即可。但,如果事务需要跨分片操作时,比如将b的值赋给y,那事情将变得复杂(分布式事务)。
2. 事务
接下来,将主要介绍Spanner中事务的实现。
Spanner将事务分为以下4种,每种都采用不同的处理方式。
2.1. 读写事务
假设有如下读写事务:
1 | BEGIN |
如果x和y在同一分片内,那事情会相对简单一些。只需要执行一个本地单机事务,而后通过Paxos算法将状态变更同步到各个副本服务器即可。
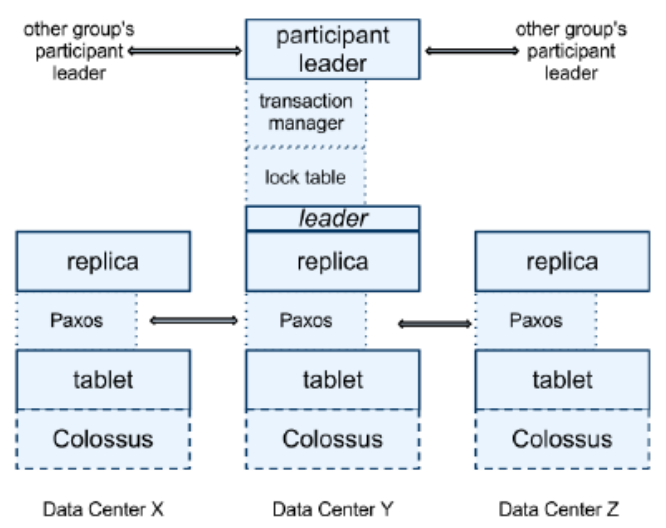
在此,我们考虑更复杂的情况,即分布式事务,x和y不在同一分片。每个分片都有1个Paxos组,组内有3个副本,各自分布在3个数据中心,粉红色的为组内leader,如下:
从之前分布式事务的博客中可知,为了保证分布式事务的原子性,最通用的方法是两阶段提交2PC;为了保证隔离性,最通用的方法是两段锁2PL。Spanner中基本也是如此。
由于Spanner中每个分片都有一个对应的Paxos组,因此在分布式事务中,一个Paxos组充当一个协调者或参与者。实际上,最终由各个Paxos组中的leader负责处理客户端的请求,以及分布式事务的协调。
针对上述分布式事务,具体执行步骤如下:
客户端为事务指定一个事务ID,用于标识这个事务。
客户端向数据x所在分片对应的Paxos组1请求读取x,Paxos组1的leader会返回x的值,并对x加读锁。同样,它再向Paxos组2请求读取数据y。注:分布式事务中的读操作是不需要请求协调者的,客户端完成所有读操作,并缓存所有写操作后,它才会将所有写操作交由协调者进行两阶段提交。
客户端在本地进行计算,得出x和y的最终结果。假设x和y的初始值都是10,那么最终x=11,y=9。
2PC准备阶段:
客户端请求事务的协调者,获取协调者的ID,将所有要进行的写操作(x=11, y=9)一次性告知协调者。假设当前事务的协调者是Paxos组1,那么这次请求将会发给Paxos组1的leader。
客户端负责将各个写操作发送给对应分片的Paxos组(包括协调者和参与者),同时还会携带协调者ID。比如,客户端会将写操作y=9发送给Paxos组2的leader。注:由客户端发送各个写操作,可减少协调者压力。
各个Paxos组的leader收到写请求后:
对数据加写锁。
发送Prepare消息给各个follower,并记录在Paxos日志中。
当它收到大多数follower的成功响应后(日志已提交),它会告诉协调者,它已经准备好了。
2PC提交阶段:
当协调者收到全部参与者对于Prepare阶段的Yes响应后,它会决定Commit。当部分参与者响应No,或者超时未响应,它就会决定Abort。假设,它决定Commit:
协调者leader会向follower发送Commit消息,并记录到Paxos日志中(保证容错,即使leader崩溃,新的leader也不会忘记当初的决定,继续该事务)。
当大多数follower成功响应(Paxos日志提交成功)后,协调者才会告诉其它参与者,可以提交该事务了。
各个参与者(Paxos组的leader)收到Commit消息后:
将Commit消息记录到Paxos日志中(发送给follower),并保证已提交。
当Commit消息已提交后,参与者才会执行对应写操作(leader将状态变更日志同步给follower),并释放锁。
相比于传统的分布式事务,Spanner分布式事务中每一个分片是一个Paxos组。因此,在2PC过程中,参与者或协调者的每一次操作都需要提交到Paxos日志。
由于Paxos算法的高容错特性,且各个副本较为分散,Spanner中分布式事务具有以下优点:
参与者或协调者的Paxos组中,只要有超半数的服务器存活,参与者或协调者就能正常工作。因为就算leader崩溃后,follower能快速成为新leader,继续进行后续操作。
能有效避免在Commit阶段,协调者崩溃或网络阻塞后,参与者一直等待的情况。因为协调者leader崩溃或网络阻塞后,新leader能快速替代它。
当然它也有缺点:由于要提交Paxos日志,而副本又分散在各个数据中心,因此通信成本非常高。在Spanner论文中有关于这方面的测试,每个Paxos组中的副本都分布在跨城市的数据中心,一次跨分片的读写事务耗时为100ms。不过,通过数据分片,可以并行处理许多不相交的分布式读写事务。另外,数据中心相隔较近的话(这种布局更为常见,许多应用并不需要把数据分散到全球),性能也会大幅提高。
2.2. 只读事务
只读事务是指一个事务中只存在读操作,可能是读一个分片内的数据,也可能是读多个分片的数据。在现实生活中,只读事务发生的次数要远远大于读写事务,因此它的性能要求远高于读写事务。
为了提高性能,Spanner对只读事务有如下设计:
只读事务可以从本地数据中心的副本读取数据,提高读取速度。但问题在于,本地数据中心的副本可能不是最新的。
不需要加锁,更不需要两阶段提交,避免了跨数据中心的通信。
但是,为了保证正确性,只读事务需要满足以下特性(约束):
事务的串行化(隔离性),所有事务就像串行执行一样。虽然只读事务可以跟读写事务并行执行(因为只读事务不加锁),但只读事务只能看到上一个已提交的读写事务执行后的结果,它不能看到处于未提交事务中间状态的数据。
副本的外部一致性(线性一致性)。当一个读写事务提交后,下一个事务应该看到所有最新的修改。在单机数据库中,一个事务提交,下一个事务一定能看到最新的修改。但在多副本的情况,并不是每一个副本的数据都是最新的,因为Paxos算法只需要超半数的副本同步成功即可。
快照隔离——保证事务隔离性
由于只读事务不加锁,在并行的场景,就会出现无法串行化情况。示例如下,Wx表示写x,Rx表示读x,C表示事务提交。
1 | T1: Wx=9 Wy=11 C |
假设x是用户的一个银行账户余额为10,y是另一个银行账户余额也为10,初始总余额是20。有三个事务,T1和T2都是读写事务,T3是只读事务。由于没加锁,T3执行过程中,Rx读取到的是T1事务执行后x的值9,而Ry读取到的是T2事务执行后y的值12。此时,用户会发现他的两个银行账户的总余额为21,这肯定是不正确的。那为什么呢?因为对这三个事务,我们无法得到一个可串行化的顺序,既不是T1 T2 T3,也不是T1 T3 T2。
为了解决上述问题,有一种方法称为 快照隔离(Snapshot Isolation, SI) ,这称为 多版本并发控制(MVCC) 。
首先,我们需要一种机制对事务进行排序:
假设参与事务的每台机器上都有一个时钟,且相互同步。
为每一个事务都分配一个特定的时间(时间戳)。假设,读写事务的时间戳是它提交的时间,只读事务的时间戳就是它开始的时间。
根据事务的时间戳对事务进行排序。对于上述示例,事务排序的结果为:
T1 T3 T2。按照该顺序执行,T3的Rx将读到10,Ry将读到10。但由于T3执行过程中,T2执行并提交了,如何保证T3不受T2影响才是问题的关键。
然后,规定每条数据记录都有多个版本,每个版本通过时间戳标识。当对某条数据记录写入时,写入结果会另存为一个单独的记录副本(快照),副本的时间戳即为事务的时间戳。当读取某条数据记录时,它会读取小于当前事务时间戳且时间戳最新的记录副本。因此,只读事务只会看到,从它开始的那一刻之前,上一个已提交读写事务执行后的最新的值。而过程中即便有其它读写事务提交,它也不会看到修改的值。
回到上述示例,假设T1的时间戳为10(提交时间),T2的时间戳为20(提交时间),T3的时间戳为15(开始时间):
1 | T1@10: Wx=9 Wy=11 C |
每个读写事务执行完,旧数据并不会被覆盖,而是会为记录创建一个新的副本:
1 | x@0 = 10, y@0 = 10 // 初始时间戳为0,记录的初始状态 |
当只读事务T3开始执行时,时间戳为15。它读取x时,系统返回时间戳小于15且最新的记录副本,也就是x@10 = 9。当它读取y时,即便T2已提交,它也看不到T2写入的y的新值,系统只会返回y@10 = 11。如此,用户读取到的值,才是正确的。这三个事务的执行,也符合串行化的顺序T1 T3 T2。
快照隔离是一种空间换时间的方法,它会浪费一定的存储空间,但系统也会定期地清理太过时的记录副本。
safe time——保证分布式一致性
由于只读事务被允许从本地数据中心读取数据,而本地数据中心的副本可能并不是最新的(Paxos算法)。比如,执行T3的Rx时,本地数据中心的副本还未同步T1的更改,x值依旧为最初状态x@0 = 10。
为了解决这个问题,Spanner提出了safe time。每个Paxos组中,leader在同步状态变更日志给follower时,会携带时间戳(递增的)。follower会将最新收到的日志时间戳作为safe time,能够保证的是,follower肯定知晓safe time之前的所有更改。因此,当只读事务的时间戳小于等于safe time时,follower肯定能返回该事务开始前最新的数据状态。反之,follower则会等待新日志。
考虑上述示例,当客户端向本地数据中心的follower副本发起事务T3(时间戳为15)时,follower的safe time为0,x的状态为x@0 = 10,它会等待leader的新日志。直到新日志的时间戳大于等于15,follower才会将x的值返回给客户端。
关于safe time的问题:
日志的时间戳与事务时间戳相等吗?应该是不相等的,比如事务T1的提交时间戳为10,但leader发送相关状态变更日志(比如
W(x@10)=9)的时间戳,可能稍微大于T1的时间戳。另外,论文中提到:$t_{safe} = min(t^{Paxos}_{safe}, t^{Tx}_{safe})$,真正safe time是Paxos safe time和事务safe time的最小值。如果一直没有状态更新,leader一直没发送新的日志,难道就一直阻塞不响应只读事务吗?
2.3. 快照读事务
只读事务是读取事务开始时间之前,最新的快照。而快照读事务,就是读取指定的快照。
3. 时钟同步
在设计保证只读事务的正确性时,有一个非常关键的前提——每台服务器上的时钟必须同步。
时钟不同步的影响
我们先考虑,如果时钟不同步,这会引发什么问题?对于读写事务而言,由于使用了锁,它们不会受到影响。关键是对只读事务的影响:
如果收到只读事务请求的服务器分配给它的时间戳,比正常时间晚。那么只读事务将会比正常的safe time大,它将等待更长的时间。比如,此刻正常时间是15,但副本服务器的时间是20,它分配给此刻只读事务的时间戳将为20,而safe time是16,只读事务只能等待safe time大于等于20。这种情况下,只读事务的延迟会增加,但不会出现错误。
如果服务器分配给只读事务的时间戳,比正常时间早。那么只读事务将无法保证分布式一致性,它将读到过期版本的数据。比如,此刻正常时间是15,但服务器的时间是10,它分配给此刻只读事务的时间`戳将为10。如果数据有
@10和@15两个版本,它将读取到@10版本的数据,而正常应该读取@15版本的数据。
而实际上,各个服务器的时钟并不同步,每台服务器的时钟都会有偏差,为什么呢?因为计算机时钟会出现偏移,每台计算机的时钟并非按照相同的速率前进。
一种保证时钟同步的方法是:大家都与一个时钟精准的服务器同步时钟。但这种方法存在通信延迟,特别是这个服务器相隔较远时。而且,这个服务器的负载将会很高。
Spanner的黑科技——TrueTime
为了解决时钟同步的问题,就不得不提Spanner的核心技术——TrueTime,下图是它的主要接口。

TT.now()会返回一个时间区间,并保证当前时间在这个区间内。区间的宽度,是通过测量网络延迟、时钟偏移、GPS误差等数据计算出来的。这个宽度通常是微秒级别,但有时也会是毫秒级别。
为了提供TrueTime API,Spanner在每个数据中心都会放置多个高精度的时间戳服务器。这些服务器采用GPS或者原子钟的方式保证时钟准确,通常会使用GPS的方式,GPS会接收政府实验室广播的高精度时间(UTC),但GPS失效时,会使用原子钟的方式。并且,相互之间会进行时钟同步。数据中心内的其它服务器会时不时与这些时间戳服务器通信,来保证自己时钟的同步。
TrueTime如何保证事务顺序
为了保证外部一致性(副本间的线性一致性),就需要给所有事务排序:如果事务T2在事务T1提交后开始执行,那么T2的时间戳一定比T1的时间戳大。
为了实现这一点,Spanner制定了两条规则:
Start。设置事务的时间戳S时,
S = TT.now().latest。对于读写事务,它的时间戳是在协调者向参与者和客户端发送Commit请求后设置的。对于只读事务,它的时间戳是在事务开始时设置的。Commit wait。读写事务中,协调者发起Commit请求后,各个Paxos组(包括参与者和协调者)的leader,必须等到
TT.after(S)为真,才将事务结果记录到Paxos日志中,并向follower同步。这样做的原因是TT.now()返回的是一个区间,那么S = TT.now().latest就可能比正常时间要大,比如:此时时间是10,而TT.now().latest可能是11,那就必须要等到11才能将事务结果写入各个副本。这就确保了客户端在时间戳S之前,不能看到任何事务提交的数据。
4. 总结
Spanner的出现对当时产生了非常大的影响,它的优势在于:作为一个全球性的分布式数据库,它不仅支持多副本+分布式事务,还提供了高性能的只读事务。
对于读写事务,Spanner采用了分布式事务常规的2PL+2PC,但引入Paxos实现了多副本,并通过Paxos避免了2PC中一直阻塞等待的情况。
对于只读事务,Spanner通过不加锁和从本地副本读取,将只读事务的性能提高了10倍。接着,它又通过快照隔离(MVCC)保证了事务隔离性,通过safe time保证了副本的一致性。而为了实现快照隔离和safe time,它又设计了特有的时间戳机制,保证了事务的全局排序和外部一致性。