分布式之MapReduce
论文:Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[J]. 2004.
前言
MIT6.824分布式课程第一课的课前阅读要求。
MapReduce是谷歌提出的面向大规模数据的分布式并行计算模式,给大数据并行计算带来了革命性影响,MapReduce也是著名的Hadoop中相当重要的一部分。
论文解读
Abstract
MapReduce用于大数据的计算。
用户可定义一个 map 函数,用于处理一个键值对,并生成一堆中间键值对;同时,用户再定义一个 reduce 函数,它用于合并所有 key 相同的中间键值对。
1 Introduction
map 和 reduct 的设计理念受 Lisp 等函数式语言的启发。
我们意识到大部分计算都可以:先用一个 map 操作去计算输入中的每个逻辑单位,得出一个包含中间态键值对的集合;然后再用一个 reduce 操作去合并所有 key 相同的 value 。
We realized that most of our computations involved applying a map operation to each logical “record” in our input in order to compute a set of intermediate key/value pairs, and then applying a reduce operation to all the values that shared the same key, in order to combine the derived data appropriately.
容错的主要机制:重新执行。
第2节介绍基础的程序模型和几个样例;第3节介绍在集群计算环境下, MapReduce 接口的简单实现;第4节介绍几种我们认为有用的程序模型的改良;第5节展示在各种各样任务上的测量;第6节展示 MapReduce 在谷歌内部的使用,包括使用经验;第7节讨论未来相关的工作。
2 Programming Model
程序的输入和输出都是键值对集合。使用 MapReduce 的用户需要将计算过程表示成两个函数:Map 和 Reduce 。
- Map 函数。由用户自定义,输入一个键值对,进行处理后,输出一组中间键值对。MapReduce 会将其中 key 相同的键值对的 value 合并起来,关联到同一个 key ,并将其传给 Reduce 函数。
- Reduce 函数。也由用户自定义,接收一个中间键值对的 key 和该 key 对应的一组 value 。Reduce 会将这些 value 合并起来,输出一组新的 value ,不过通常它只输出零或一个值。输入中的一组 value 会通过一个迭代器传递,防止数据量太大而导致内存无法容纳。
2.1 Example
统计大量文档中各单词出现的次数:
1 | map(String key, String value): |
2.2 Types
1 | map (k1,v1) → list(k2,v2) |
map函数输入的键值对(k1,v1) 和输出的中间键值对(k2,v2)属于不同域,比如在上述示例中:对于map函数,(k1,v1)是文档名和文档内容,而(k2,v2)则是单词和出现次数,;而对于reduce函数,输入的v2是单词出现次数,输出也是单词出现次数,属于同一域。
2.3 More Examples
- Distributed Grep:map函数输出被匹配的行,reduce函数则只是拷贝输入到输出。
- Count of URL Access Frequency:map输入请求日志并输出
<URL, 1>,reduce求和URL相同的键值对的值并输出<URL, total count>。 - Reverse Web-Link Graph:map函数输出
<target, source>,target是指向目标URL的链接,source是链接所在页面的名称;reduce函数将所有target相同的source集合起来,输出<target, list(source)>。 - Term-Vector per Host
- Inverted Index
- Distributed Sort
3 Implementation
本节所介绍的MapReduce实现将基于大规模计算机集群。
3.1 Execution Overview
Map函数分布在多个机器上,输入数据将被自动分为M片,每一片可被不同机器并行地处理。中间键值对通过一个分区函数(partitioning function)分为R片,R和分区函数由用户自定义。
MapReduce调用过程如下:
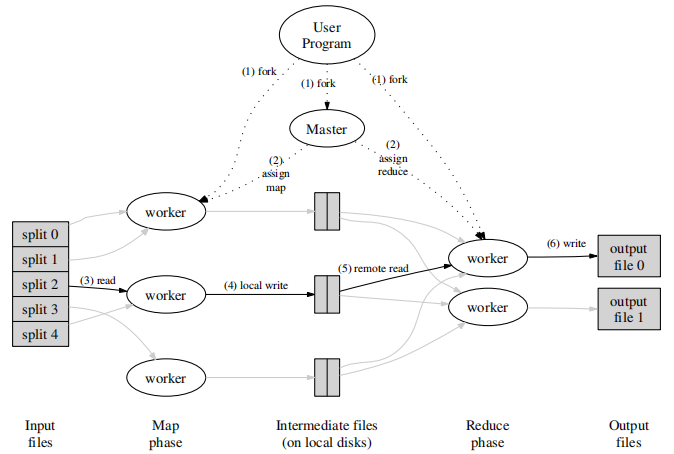
- MapReduce库先将输入文件分为M片,每片通常16MB到64MB。然后它将唤醒程序对应的集群。
- 集群存在一个特殊的节点master,其余都为worker。总共有M个Map任务和R个Reduce任务,由master分配给相应的worker。
- 负责Map任务的worker,从对应的片段中读取输入数据(M个Map worker与输入的M个片段一一对应)。它从输入中解析出键值对,然后将每一个传递给用户定义的Map函数。Map函数处理后输出中间键值对,并缓存在内存中。
- 缓存的中间键值对会周期性地写入磁盘中,并被分区函数(比如
hash(key) mod R,保证不同map输出的相同key都在同一个序号的分区中)分为R个分区(对应R个Reduce任务,比如第i个分区对应第i个Reduce)。这些缓存的中间键值对的位置会被告知给master,master会将位置传达给Reduce worker。 - 当Reduce worker被master告知中间键值对位置后,它会通过远程调用读取对应Map worker磁盘中的数据(第i个Reduce读取所有Map中第i个分区的数据)。当Reduce worker读取了所有的中间键值对,它会根据key进行排序 ,因此相同key的中间键值对会组合在一起。如果数据量太大无法放入内存,则需进行外部排序。
- Reduce worker会遍历排好序的中间键值对,将每一个唯一的key和对应的一组value传递给用户定义的Reduce函数,输出结果将追加到当前reduce分区对应的最终文件。
- 当所有map和reduce任务完成,master将唤醒并返回用户程序。
当MapReduce成功执行完成,结果将会存放在R个输出文件中(对应Reduce任务个数)。用户并不需要合并这R个文件,它们通常会作为下一个MapReduce任务的输入或者应用到下一个分布式任务。
3.2 Master Data Structures
master节点保存每个map和reduce任务的状态、每态计算机的标识、已完成的map worker的输出数据的位置和大小。
3.3 Fault Tolerance
Worker Failure
master定期ping每一个worker,如果某个worker一段时间内没有响应,则将其标记为failed失败。
对于失败worker中的map任务,不管任务已完成还是在进行中,都将被重置为idle初始状态,并分配给另一个worker。 因为,失败worker中map任务的输出被保存在失败worker电脑的本地磁盘。
对于失败worker中的reduce任务,若任务已完成则不需要被重新执行,因为它们的输出被保存在全局文件系统。
当一个map任务先被worker A执行再被worker B执行(A出现异常)时,所有从A读取输入数据的正在执行的reduce任务将被通知重新执行。
Master Failure
将master的相关数据周期性地写入checkpoint检查点,如果master失效,一个新的副本将从最近一次的checkpoint启动。然而,master只有一个节点,是不可能失效的(?)。如果master失效,将中止MapReduce计算。客户端可检查此条件,并重试MapReduce计算。
It is easy to make the master write periodic checkpoints of the master data structures described above. If the master task dies, a new copy can be started from the last checkpointed state. However, given that there is only a single master, its failure is unlikely; therefore our current implementation aborts the MapReduce computation if the master fails. Clients can check for this condition and retry the MapReduce operation if they desire.
Semantics in the Presence of Failures
map和reduce任务的提交都是原子操作。
每一个正在运行的任务会将输出写到私有的暂存文件中 ,reduce任务产生一个这样的文件,map任务产生R个这样的文件(每个对应一个reduce任务?)。
当map任务完成时,worker会向master发送一条消息,包含R个暂存文件的名字 。如果master已接受过该消息,则忽略,否则将消息数据记录到本地。
当reduce任务完成时,worker会原子地将其输出的暂存文件重命名为最终输出文件 。如果相同的reduce任务被多台机器执行,多个重命名操作会被执行在最终输出文件上,但由于原子性,我们能保证最终文件仅包含一个reduce任务所产生的数据。
3.4 Locality
master在调度map任务时会考虑输入数据文件的位置信息。尽量在包含该相关输入数据的副本的机器上执行map任务。如果任务失败,master会尝试在保存输入数据副本的邻近机器上执行map任务(比如同一网络中)。
3.5 Task Granularity
我们将map任务划分成M个,reduce任务划分成R个,同时M和R远远大于worker的数量。
master必须执行O(M+R)次调度,并在内存中保存O(M*R)个状态。
R通常由用户定义,因为最终会有R个输出文件。实际中,M的值会保证每份独立的输入数据在16MB在64MB之间,R的值则应该是worker的倍数。比如:2000个worker,M=200000,R=5000。
3.6 Backup Tasks
导致MapReduce总时间延长的一个常见原因是存在“落伍者”——一台机器在执行最后几个map或reduce时,花费了比平时更长的时间。“落伍者”出现的原因有很多,比如磁盘出现了错误,读写速度从30MB/s下降到1MB/s。
我们有一个常用方法来解决“落伍者”问题,当MapReduce任务快完成时,master将会备份执行 正在运行中的剩余任务,只要主任务或备份任务完成,任务就会被标记为已完成。
使用该机制只会比不使用多花费几个百分比的计算资源,但能显著减少运行大型计算所需要的时间。
4 Refinements
4.1 Partitioning Function
reduce任务/输出文件数量R由用户定义,中间键值对被分区函数分为R份。一个默认的分区函数通常使用HASH,比如:hash(key) mod R,再比如:中间key是URL,且想要域名相同的最终在一个输出文件中,分区函数可定义为hash(Hostname(urlkey)) mod R。
4.2 Ordering Guarantees
对于一个给定的分区,中间键值对会根据key升序排列。这种顺序能保证分区对应的输出文件是有序的。有时这很有用。
4.3 Combiner Function
在很多情况下,不同map任务会产生相同的中间键值对。比如在单词统计的MapReduce程序中,每个map任务都会产生数以千计的<the, 1>键值对,所有这些键值对会被发送给单个reduce任务。我们允许用户定义一个Combiner函数,在数据发送之前,可以通过该函数将数据进行部分合并 。
Combiner函数在map任务运行的每台机器上执行。通常Combiner函数和Reduce函数代码一样(?),不同在于Reduce函数输出到最终文件,Combiner函数输出到中间文件。
部分合并会明显提升某类MapReduce操作的速度。
4.4 Input and Output Types
MapReduce支持读取不同形式的输入数据,例如:对于文本数据,每一行当作一对key/value。
用户可以使用预定义的输入格式,也可以实现reader接口用来支持新的输入格式。reader函数不仅可以从文件中读取数据,也可以从数据库、内存中读取。
同样,我们也提供预定义的输出格式用于产生输出,当然用户也可以自定义。
4.5 Side-effects
在某些情况下,用户为了便利,会在执行map或reduce任务时产生额外的辅助文件。我们需要用户保证这些副作用(side-effects)的原子性和幂等性(idempotent)。
我们不支持一个任务产生多个输出文件所带来的两段原子提交。。。(没搞懂,原文如下)
We do not provide support for atomic two-phase commits of multiple output fifiles produced by a single task.Therefore, tasks that produce multiple output fifiles withcross-fifile consistency requirements should be deterministic. This restriction has never been an issue in practice.
4.6 Skipping Bad Records
有时,某个记录(record)会导致Map或Reduce函数崩溃,这些bug会阻止MapReduce的完成。
通常的方法是去修复这个bug,但有时候是不可修复的,比如bug在第三方库中。我们提供了一种可选的执行模式 ,MapReduce检测到某个记录会导致崩溃时,将会跳过这个记录。
具体细节是,worker上运行一个捕获内存段异常(segmentation violation)和总线错误(bus error)的handler。在调用Map或Reduce函数之前,MapReduce会保存参数的序号。如果程序产生错误信号(signal),handler就会向master发送一个包含参数序号的”last gasp”UDP包。如果master发现这个记录出现了不止一次错误,就会标记这个记录,并让重新执行的Map或Reduce任务跳过它。
4.7 Local Execution
调试分布式系统是一个棘手的问题,为了方便调试,我们实现了另一种MapReduce——可以在本地机器上顺序执行所有操作。
4.8 Status Information
在master中,运行着一个HTTP服务器,它向用户展示一些状态页面。这些状态页面展示计算的进度,比如:how many tasks have been completed, how many are inprogress, bytes of input, bytes of intermediate data, bytes of output, processing rates, etc。页面还包含每个任务产生的错误和输出文件的链接。用户可以通过页面估计时间、添加计算资源、分析调试等等。
4.9 Counters
MapReduce还提供计数器counter用于记录不同事件发生的次数,比如已处理单词的个数。
1 | Counter* uppercase; |
每隔一段时间,计数器的值会从不同worker上报给master。来自已成功完成的map和reduce任务的counter值,会被master集合起来,并在MapReduce完成后返回给用户代码。同时,counter值也在状态页面展示给用户。聚合counter值时,master会剔除重复执行的任务。
5 Performance
略
6 Experience
略
7 Related Work
略
8 Conclusions
MapReduce成功的原因:
- 易于使用(抽象性好)。
- 很多问题都能用MapReduce表示。
- 已经成熟,可以扩展到数千台机器上使用。
这项工作中的启发:
- 通过限制编程模式 可以让并行分布式计算和计算容错更加容易。
- 网络是一种紧缺资源 。因此我们进行了许多优化,比如:从本地读取数据、将中间数据暂存到本地。
- 可以使用冗余执行 ,来减少速度比较慢的机器所带来的影响,以及处理计算机故障和数据丢失。