比特币中的重难点
1. 比特币地址
比特币地址是资金接收者的地址,相当于收款人的银行账号。它并非直接等于收款人的公钥,而是需要经过一定的转换,转换过程如下:
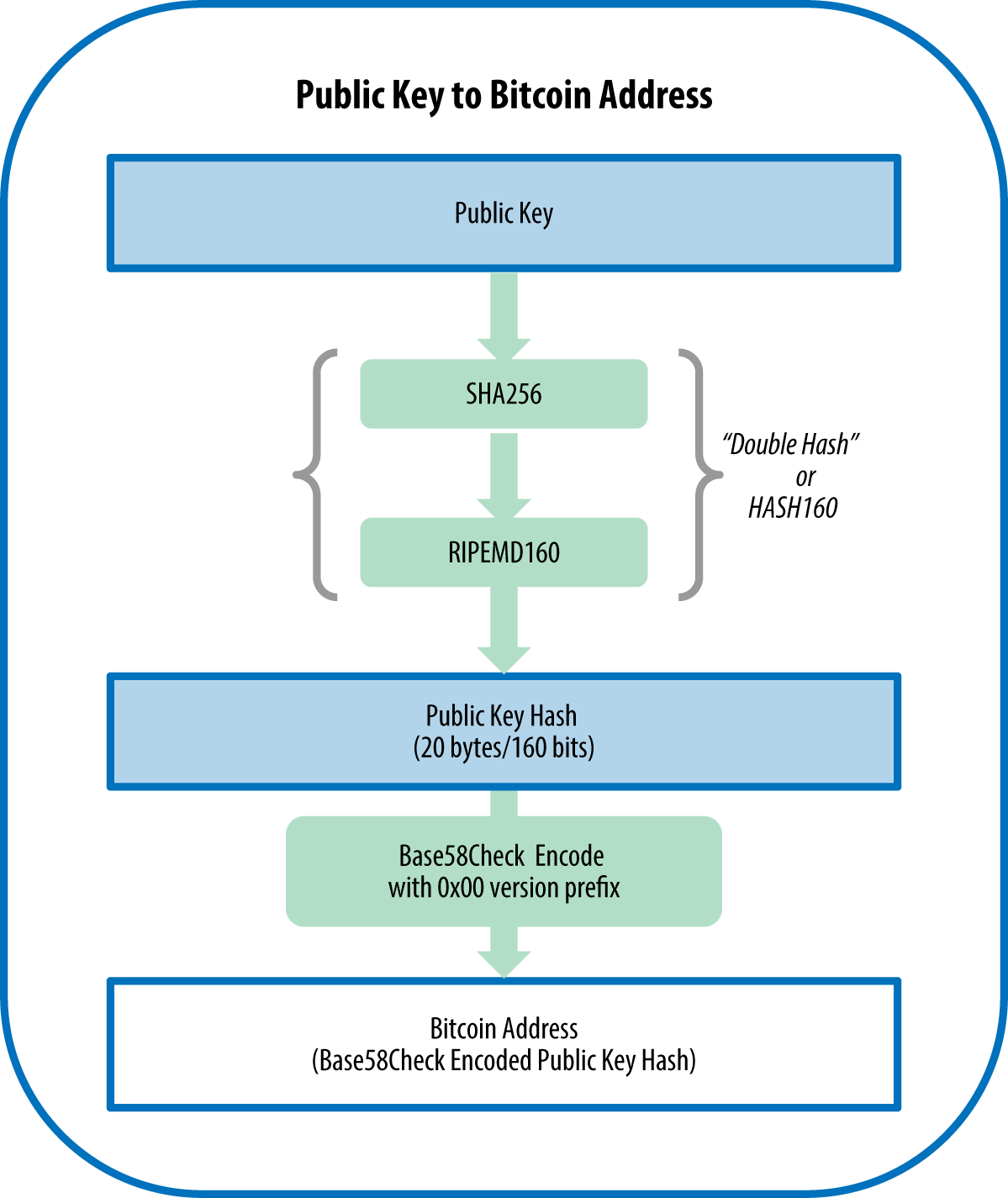
注意:
比特币的公钥是由私钥根据椭圆曲线加密算法计算出来的,其反向运算是非常困难的,只能通过暴力搜索。
为什么比特币地址要对公钥进行哈希,而不直接使用公钥?因为哈希是不可逆的,比如在SHA256哈希过程中,源数据的部分信息会丢失,不然无法保证任意输入的输出值都为256位。所以我们无法通过比特币地址推导出用户公钥,即使量子计算机也不可以,这就能防止用户公钥泄露(公钥是有可能推出私钥的)。
2. 交易脚本
在比特币区块数据中,一笔交易会以如下形式存储:
1 | { |
在这笔交易中,有1个输入、2个输出。
每个输入的结构如下:
txid:指向上一笔交易(UTXO)的ID
vout:用于指明使用上一笔交易中的哪个输出
scriptSig:解锁脚本
sequence:序列号,Used for locktime or disabled (0xFFFFFFFF)
每个输出的结构如下:
value:输出比特币的值
scriptPubKey:锁定脚本
可以看到在一笔交易中,并未直接明了地给出交易双方的地址或公钥等信息,那么如何验证交易的有效性呢?这就不得不提到比特币的交易脚本语言,它是一种基于堆栈的执行语言。当一笔交易被验证时,交易中每一个输入的解锁脚本,与上一笔交易中对应输出的锁定脚本一起执行,以此验证这笔交易是否有效。
下图是最常见交易(P2PKH, Pay-to-Public-Key-Hash)的解锁脚本(在当前交易的输入中)和锁定脚本(在上一笔交易的输出中)示例:

其中<sig>是当前交易付款方的签名;<PubK>是当前交易付款方的公钥;<PubKHash>是付款方公钥的哈希,也就是付款方(上一笔交易的收款方)的比特币地址。
脚本组合之后,从左往右执行,执行环境是在一个栈中。当遇到<xxx>时,直接将值压入栈中。DUP是将栈顶值复制一份再压入栈。HASH160是将栈顶值进行HASH160运算,即由公钥得到比特币地址。EQUALVERIFY是验证栈顶两个值是否相等。CHECKSIG是用公钥验证签名是否正确。
注意:
- 交易输入的解锁脚本中会暴露付款方的公钥,为了保护公钥进而保护私钥,用户可以生成多个公钥,交易的找零输出中可以找零到自己的新地址(通常每次交易时,钱包都会生成一个新找零地址)。
3. Bloom过滤器
对于轻节点,通常只保存最近少数几个区块的区块头。当它想知道与它相关的交易是否生效(被写入区块链中)时,它需要委托全节点将与它相关的交易所在的区块头和merkle路径转发过来。但是,轻节点又不想暴露它的地址。为了保护轻节点隐私,同时又能让全节点筛选出与轻节点地址相关的交易,比特币使用了布隆(Bloom)过滤器。
布隆过滤器由一个集合生成,当某个元素经过布隆过滤器时,会得出两种结果Yes或No。Yes可以判断出元素可能存在集合中,No则能判断出元素肯定不在集合中。
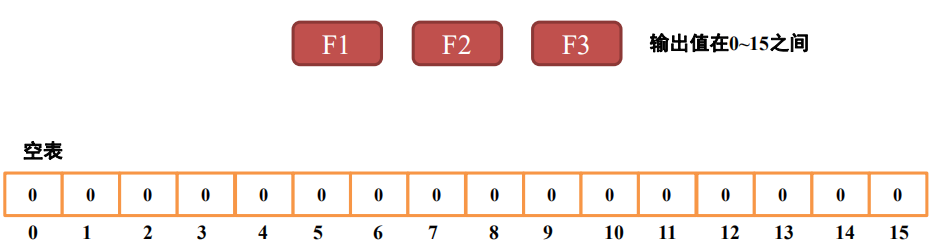
布隆过滤器由一个长度为N的bit数组和M个哈希函数组成,数组中每个bit对应的初始值都为0。如下,是一个N=16, M=3的例子:
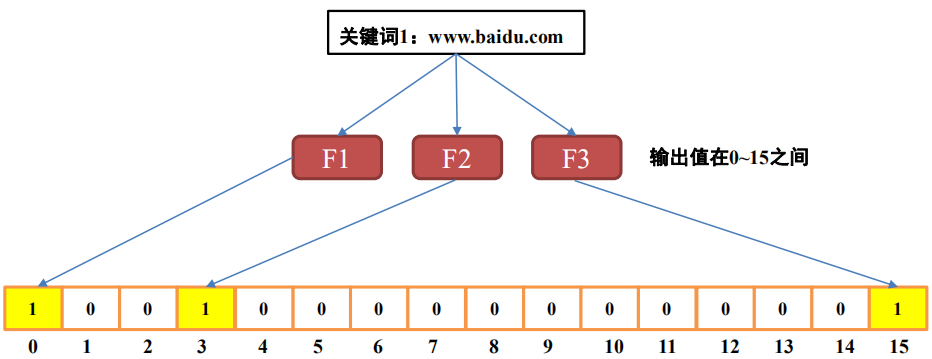
生成布隆过滤器:将集合中每个元素经过三个哈希函数,并将结果映射位置的值置为1。如下图,集合中有三个网址,将它们映射并生成bit数组:
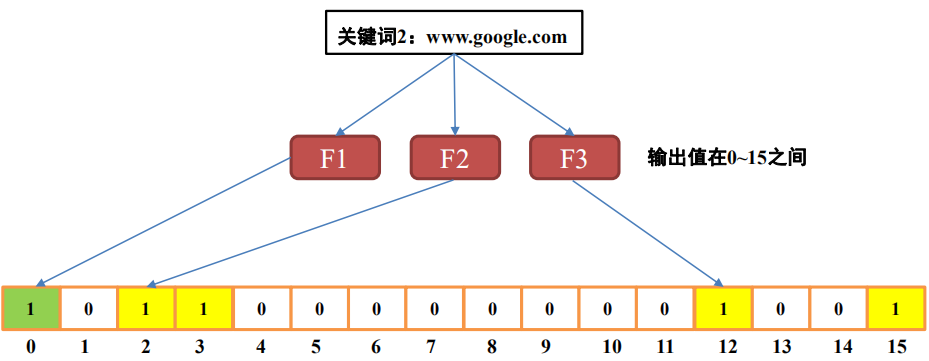
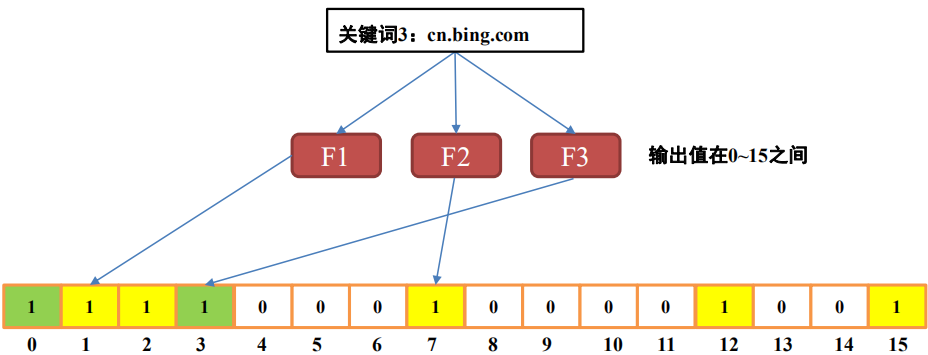
根据生成的bit数组,对于一个新元素,若经过三个哈希函数映射位置的值都为1,那能说明该元素可能存在于集合中;若映射位置的值不都为1,那说明该元素一定不在集合中。
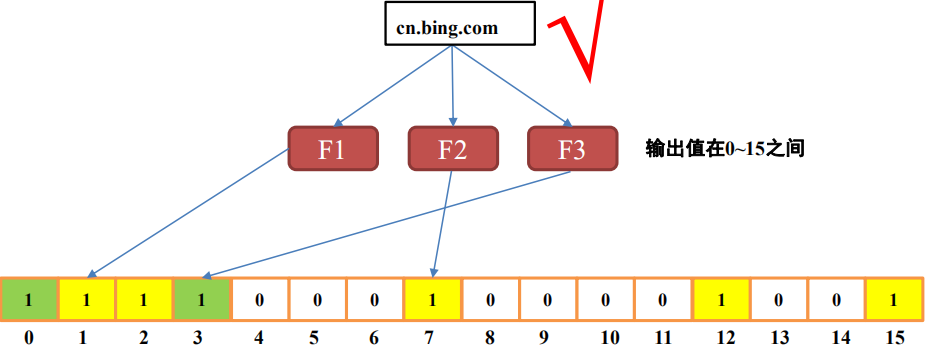
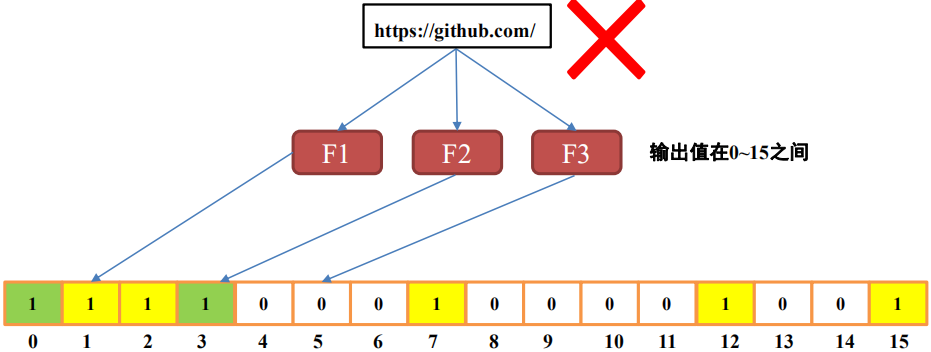
根据其性质,布隆过滤器存在误判的可能性,即不能判断一个元素一定在集合中。但随着哈希函数个数和数组长度的增大,误判发生的概率就越小。并且,在某些场景下,不需要准确地判定元素一定存在集合中。
回到一开始的场景,轻节点只需将它的地址混在多个随机地址的集合中,以此生成布隆过滤器。再将此布隆过滤器发送给全节点,全节点会根据布隆过滤器筛选,将符合过滤器的信息返回给轻节点。轻节点再从其中找出真正与自己相关的信息,完成验证。
4. 硬分叉/软分叉
硬分叉:旧节点不认可新节点的区块。旧节点和新节点会发生永久性的分叉。
软分叉:旧节点认可新节点的区块。临时性的分叉,随着新节点增多,最终会合并。
举例:区块大小限制原先是1MB,新版本要求2MB,旧节点不认可新节点发布的区块,就会发生硬分叉;新版本若要求0.5MB,旧节点认可新节点发布的区块,是软分叉。